考试范围
后五章
记忆常见的生成函数
TODO
如何找非齐次线性递推关系的特解? PPT 14页
一些题目
- 假设有一个由 个不同元素组成的多重集, 每个元素可以重复无限次. 求从中选择 个元素, 且每种元素至少选择一次的组合数.
Answer
先每种元素各取一个, 剩下还要取个, 这个时候就可重复组合问题, 使用星星隔板法就能得到数目为
- 考虑一个由 个不同元素的集合. 求它的所有大小为偶数的子集的总数. 尝试使用二项式定理的性质来解决这个问题.
Answer
就是要求, 将和的展开式加起来除以即可, 答案是
- 求解以下的非齐次线性递推关系:
给定初始条件 和 .
Tip
这里的特解可以直接通过解方程得到.
- 分析复杂度
Tip
注意第二个递推式适用的是主定理的第二种情况, 而不是第三种. 尽管, 但是我们找不到一个使得. 所以最后的复杂度是.
- 给出一个由主定理无法解决的递推关系, 并说明原因.
Answer
如
- 已知, 求的满射函数有多少个
Answer
由容斥原理有
- 证明只有种正多面体
Answer
设顶点数为, 边数为, 面数为, 每个顶点的度数为, 每个面的度数为, 则由欧拉定理, ; 由握手定理, 于是就有.
这里有个约束是. 因为当时, 每个面是一个正六边形, 这时候正好铺成一个平面, 不能再形成立体图形了, 并且显然有, 于是只能取.
计数
二项式定理
取特殊值
Pascal恒等式
就是杨辉三角的构造规则
Vandermonde恒等式
从 个男生和 个女生中选取 个人, 可以直接从 个人中选出 人, 也可以分类从到, 选取个女生和个男生, 再把所有的可能的取法加起来.
当时的特例为
排列组合
多重集的排列
出现了次, 出现了次, ..., 出现了次, 一共有个元素, 那么排列数目就是
可重复的排列
一共有个元素, 要做一个排列, 那么总的方案数就是.
可重复的组合
假设我们有 种不同的元素, 我们想要从中选择 个元素, 其中每种元素可以选择多次.
我们用星号来表示元素, 条形来表示分割, 比如说 假设我们有 种元素 () 分别是 , , 和 . 我们要从中选取 个元素 (),
- 如果我们选择 个 , 个 , 和 个 , 那么我们可以表示为:
**|*|** - 如果我们选择 个 , 个 和 个 , 那么我们可以表示为:
|***|**
现在, 问题就转化为: 我们需要将 个星号和 个条形放在一起, 总共有多少种不同的排列方式.
多重集的组合
即可重复的组合+每个元素有重复上限. 没有一般的公式, 使用容斥原理:
假设我们有 , 并且我们要选出 个元素.
- **无限制的情况: ** (即可重复组合的公式)
- 违反限制情况:
- (超过个限制, 也就是选了个, 我们先选个, 剩下的, )
- (超过个限制, 那么就先个, 剩下的)
- (超过个限制)
- 注意, 如果参数为负, 组合数就是0.因为我们不可能同时多选超过所有元素数量限制的元素
- 同理, , , 和 .
- 容斥原理:
- 最后结果 =
所以答案是, 也就是
abc,aab,acc这三种
- 最后结果 =
所以答案是, 也就是
圆排列
认为旋转等价, 个元素的圆排列的方案数为.
项链排列
认为旋转和镜像等价, 个元素的项链排列的方案数为
Catalan数
两个定价定义
递归定义
通项公式
应用
括号匹配
表示包含对括号的合法匹配的括号表达式的数量, 例如当时, 合法的表达式有
二叉树计数
表示有个节点的不同二叉树的数列, 事实上, 上面的每一个括号匹配都对应一个二叉树
我们可以将一个二叉树的中序过程与括号匹配对应起来
def tree_to_brackets(root):
if not root:
return ""
result = "("
# Process left subtree
if root.left:
result += tree_to_brackets(root.left)
else:
result += ""
result += ")"
# Process right subtree
if root.right:
result += tree_to_brackets(root.right)
else:
result += ""
return result
例如
((()))
()
/
()
/
()
(()())
()
/
()
\
()
(())()
()
/ \
() ()
- `()(())
()
\
()
/
()
()()()
()
\
()
\
()
递推关系
求解递推关系
一般的有重根的情况
Let be real numbers. Suppose that the characteristic equation
has distinct roots with multiplicities , respectively, so that for and . Then a sequence is a solution of the recurrence relation
if and only if
for , where are constants for and that can be derived from initial conditions.
非齐次的情况
先找到特解, 和齐次解.
If is a particular solution of the non-homogeneous linear recurrence relation with constant coefficients
then every solution is of the form , where is a solution of the associated homogeneous recurrence relation
比如说对于以下非齐次递推关系
对应的齐次递推关系是
特征方程. 于是齐次解的形式为
我们再用待定系数法, 猜想的形式为, 可以解得. 那么我们可以得到通解
主定理
If each dividing and combining process of size takes a time of , the runtime of the algorithm can be expressed by the recurrence relation
The master theorem indicates that, for constants and with asymptotically positive, the following statements are true:
- Case 1. If for sone , Then
- Case 2. If , then
- Case 3. If for some (and for some for all sufficiently large), then
这个是算法中的一般形式, 离散数学中将简化为, 这个时候, 对于递推关系
- 如果, 那么 (这个时候第一个递归项是主导的)
- 如果, 那么 (这个时候两者达到一种平衡, 所以要把两项都计算进去, 每一层的工作量是, 一共有层, 也就是层)
- 如果, 那么 (这个时候第二项是主导的)
Furthermore, if we are in Case 1 when and , then
where and
对于第一种的特殊情况, 的增长速度就是, 这个时候就可以设函数具有如上的关系
生成函数
形式
Furthermore, if we are in Case 1 when and , then
where and
常见的生成函数和数列的对应关系
| 说明 | ||
|---|---|---|
| 二项式定理 | ||
| 二项式定理 | ||
| if ; 0 otherwise | 二项式定理 | |
| 1 if ; 0 otherwise | 等比数列求和 | |
| 1 | 等比数列求和的极限 | |
| 等比数列求和的极限 | ||
| 1 if ; 0 otherwise | 等比数列求和 | |
| 等比数列求和的极限公式两边求导 | ||
| 求次导 | ||
| 求次导 | ||
| 求次导 | ||
| Taylor级数 | ||
| Taylor级数 |
应用
生成函数在计数问题中的应用
线性方程解的个数
问题: 求方程的非负整数解的个数, 其中 且 .
解法: 满足约束条件的解的个数是以下表达式中 的系数:
这是因为我们通过从第一个和中选择 , 从第二个和中选择 , 从第三个和中选择, 得到乘积中的一项 . 这个乘积中 的系数是 3 .
放入自动售货机的代币方式
问题: 确定将价值$1, $2和$5的代币放入自动售货机以支付美元的物品的方式的数量, 考虑两种情况:
- 代币的插入顺序不重要.
- 代币的插入顺序重要.
解法:
-
顺序不重要: 答案是以下生成函数中 的系数:
-
顺序重要: 插入 n 个代币得到总价值 r 美元的方法数是 中 的系数. 因此, 总的插入方法数是以下生成函数中 的系数:
使用生成函数求解递归关系
问题: 求解递归关系 , 其中 , 初始条件为 .
解法: 设 为序列 的生成函数, 即 . 首先注意:
根据递归关系, 我们有:
因为 且 . 因此,
利用恒等式 , 可以得到 .
另一个例子: 求解递归关系:
仍然有:
因此
得到
使用生成函数证明恒等式
问题: 证明
解法: 首先注意到, 根据二项式定理, 是 中 的系数. 又因为
这个表达式中 的系数是:
这等于 , 因为 .
指数生成函数
对于序列 , 它的指数生成函数(e.g.f)定义为:
当元素的顺序很重要时, 例如排列或有标记的结构, 指数生成函数尤其有用. 它们允许进行类似于普通生成函数的加法和乘法运算.
例子: 求集合 的长度为 的带重复排列的指数生成函数, 其中 的数量为奇数, 的数量为偶数, 的数量为任意数. 我们考虑以下函数:
已知如果有个, 个 和个, 共有 种排列. 考虑上面乘积中 的系数. 获取 项的一种方式是:
也就是说, 这一项计算了有个, 个 和个 的排列的数量. 最终 的系数将是许多此类项的总和, 计算所有可能选择的奇数个, 偶数个和任意数量的的排列贡献.
注意:
类似地:
因此, 我们寻求的生成函数是
关系
基本性质
- 自反性:
- 对称性: .
- 非对称性: 不存在
- 反对称性:
- 传递性:
用集合符号表示
| Property | Set Restriction |
|---|---|
| Reflexive | |
| Non-reflexive | |
| Symmetric | |
| Antisymmetric | |
| Asymmetric | |
| Transitive |
元关系
定义
设 是一系列集合. 在这些集合上的一个 -元关系是 的一个子集. 集合 被称为关系的域, 而 被称为它的度.
简单来说, -元关系就是由 个集合的元素组成的元组(-tuple)构成的集合.
操作符
选择 (Selection)
设 是一个 -元关系, 是 中元素可能满足的条件. 那么选择操作符 将 -元关系 映射到由 中所有满足条件 的 -元组组成的 -元关系.
例如, 考虑一个包含学生姓名, 年龄和专业的 3-元关系. 选择操作符可以用来选择年龄大于 20 岁的学生.
投影 (Projection)
投影 , 其中 , 将 -元组 映射到 -元组 , 其中 .
例如, 一个包含学生姓名, 年龄和专业的 3-元关系, 投影操作符可以用来只保留学生的姓名和专业, 从而得到一个 2-元关系.
连接 (Join)
设 是一个度为 的关系, 是一个度为 的关系. 连接 , 其中 且 , 是一个度为 的关系, 它由所有 -元组 组成, 其中 -元组 属于 , -元组 属于 .
连接操作符基于两个关系中公共的 列进行连接, 类似于数据库中的 Join 操作.
关系的表示
- 01矩阵
- 有向图
关系的闭包
一个关系的闭包是指包含的, 并且具有某些特定性质的最小关系. 换句话说, 我们给关系添加最少量的元组, 使其满足特定的性质, 而得到的新的关系就是闭包.
自反闭包
对称闭包
, where
传递闭包
联通关系
Let be a relation on a set . The connectivity relation consists of these pairs such that there is a path of length at least one from to in .
Because consists of the pairs such that there is a path of length from to . It follows that is the union of all the sets . In other words
Now we can see that, the transitive closure of a relation equals the connectivity relation
Warshall 算法
function Warshall(A):
n = number of vertices
for k from 1 to n:
for i from 1 to n:
for j from 1 to n:
A[i][j] = A[i][j] or (A[i][k] and A[k][j])
return A等价关系
A binary relation on a set is said to be an equivalence relation, if and only if it is reflexive, symmetric and transitive. That is, for all and in :
- (reflexivity)
- (symmetry)
- (transitivity)
等价类
Let be an equivalence relation on a set . The set of all elements that are related to an element of is called the equivalence class of . The equivalence class of with respect to is denoted by . When only one relation is under consideration, we can delete the subscript and write for this equivalence class.
Let be an equivalence relation on a set . These statements for elements and of are equivalent
Let be an equivalence relation on a set . Then the equivalence classes of form a partition of . Conversely, given a partition of the set , there is an equivalence relation that has the sets , , as its equivalence classes.
Let be an equivalence relation on a set . Then the equivalence classes of form a partition of . Conversely, given a partition of the set , there is an equivalence relation that has the sets , , as its equivalence classes.
比如说将整数根据除的模进行划分, 可以通过这个建立等价类
偏序关系
定义
一个集合 上的二元关系 是偏序关系当且仅当对于任意 :
- (自反性)
- (反对称性)
- (传递性)
简单来说, 偏序关系就是一种定义在集合上的"小于等于"的关系, 它不要求集合中的任意两个元素都可比较.
如果集合中的任意两个元素都可比较, 则该偏序关系被称为全序关系
如果一个全序集的任意子集都含有一个最小的元素, 那么被称为良序集
比如说, 是良序集; 而是全序集, 却不是良序集; 自然数的整除关系就不是一个全序集.
良序归纳法
假设 是一个良序集, 我们要证明性质 对于所有 都成立. 那么, 我们只需要证明以下条件:
- 归纳步骤: 对于任意 , 如果对于所有满足 的 , 性质 都成立, 那么性质 也成立. (这里 表示 且 ).
更准确地说, 如果 , 那么 .
和一般归纳法的区别: 良序归纳法不需要显式的基本情况. 因为在良序集中总是存在最小元素, 归纳步骤"自动覆盖"了最小元素的情况. 如果 是 的最小元素(即不存在 使得 ), 在归纳步骤中, 当 时, 条件 "对于所有满足 的 , 性质 都成立"自动为真, 因为根本不存在这样的 .
Hasse 图
- 图中的每个节点代表偏序集中的一个元素
- 对于图中的边
- 如果 (即 且 ), 并且不存在另一个元素 使得 , 那么在图中, 从 到 画一条向上的边.
- 通常, 我们不会画出自反的环(即 的边)
- 我们也不画出所有传递的边, 比如, 如果 且 我们不会再画一条 的边.
- 边的方向总是向上的, 所以图中箭头可以省略.
简而言之, 哈斯图只画出覆盖关系 (covering relation). 如果 并且不存在 使得 , 那么称 被 覆盖, 用 表示这种覆盖关系.
The following figure shows the process to construct the Hasse diagram of
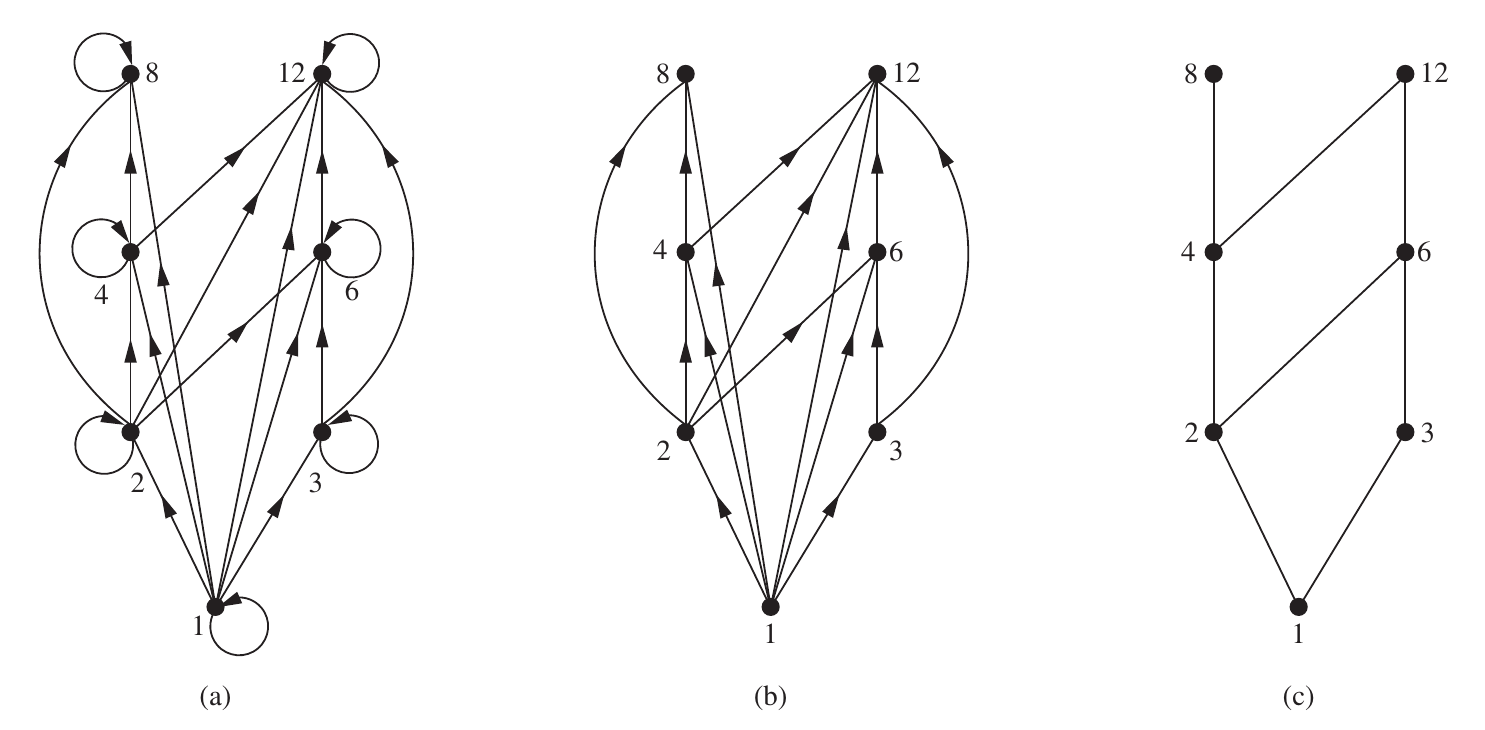
最大最小元素
极大元 (Maximal Element) 和 极小元 (Minimal Element)
- 在一个偏序集 中, 如果元素 满足不存在任何元素 使得 , 那么 就被称为 极大元. 简单来说, 没有其他元素"大于" 了.
- 在一个偏序集 中, 如果元素 满足不存在任何元素 使得 , 那么 就被称为 极小元. 简单来说, 没有其他元素"小于" 了.
- 在Hasse图中, 极大元是位于"最顶端"的元素, 而极小元则是位于"最底端"的元素.
最大元 (Greatest Element) 和 最小元 (Least Element)
- 在一个偏序集 中, 如果元素 满足对于所有 都有 , 那么 就被称为 最大元. 换句话说, 所有其他元素都"小于等于" . 如果存在最大元, 那么它是唯一的.
- 在一个偏序集 中, 如果元素 满足对于所有 都有 , 那么 就被称为 最小元. 换句话说, 所有其他元素都"大于等于". 如果存在最小元, 那么它是唯一的.
注意: 最大元一定是极大元, 最小元一定是极小元; 反之则不成立. 一个偏序集可能没有最大元或最小元, 但是可以有多个极大元或极小元.
上界 (Upper Bound) 和 下界 (Lower Bound)
- 考虑偏序集 中的一个子集 . 如果存在元素 使得对于 中所有元素 , 都有 , 那么 就被称为的一个上界. 简单来说, 上界"大于等于" 中的所有元素.
- 如果存在元素 使得对于 中所有元素 , 都有 , 那么 就被称为 的一个 下界. 简单来说, 下界"小于等于" 中的所有元素.
最小上界 (Least Upper Bound) 和 最大下界 (Greatest Lower Bound)
- 如果 是子集 的一个上界, 并且比 的所有其他上界都"小", 那么 就被称为 的 最小上界 (也称为上确界, supremum).
- 如果 是子集 的一个下界, 并且比 的所有其他下界都"大", 那么 就被称为 的 最大下界 (也称为下确界, infimum).
格
一个格(lattice)是指一个偏序集, 其中每对元素都有一个最小上界和一个最大下界.
举例来说, 正整数集合 在整除关系 下构成一个格. 对于任意两个正整数 和 :
- 它们的最小上界是它们的最小公倍数
- 它们的最大下界是它们的最大公约数
因此, 是一个格. 同理, 实数集 在标准的"小于等于"关系 下构成一个格.
- 任意两个实数 和 的最小上界是它们的较大值 .
- 任意两个实数 和 的最大下界是它们的较小值 .
拓扑排序
def topological_sort_kahn(graph):
"""
使用 Kahn 算法对有向无环图进行拓扑排序.
Args:
graph: 一个字典, 表示有向图, 键是节点, 值是该节点指向的节点列表.
例如: {'a': ['c'], 'b': ['c'], 'c': ['d'], 'e':['f'], 'd':[], 'f':[]}
Returns:
一个列表, 包含拓扑排序后的节点, 如果图中存在环, 则返回 None.
"""
in_degree = defaultdict(int) # 存储每个节点的入度
for node in graph:
for neighbor in graph[node]:
in_degree[neighbor] += 1
queue = deque([node for node in graph if in_degree[node] == 0]) # 初始时入度为0的节点入队列
result = []
while queue:
node = queue.popleft()
result.append(node)
for neighbor in graph.get(node, []):
in_degree[neighbor] -= 1
if in_degree[neighbor] == 0: # 如果邻居节点的入度变为 0 入队
queue.append(neighbor)
if len(result) != len(graph): # 如果结果列表中节点数量小于图中节点数量, 说明有环
return None
else:
return result
图
基本类型
- 简单图 (Simple Graph):
- 无向图
- 没有环(连接自己的边)
- 没有多重边(两个顶点之间超过一条边)
- 多重图 (Multigraph): 多重图允许同一对顶点之间存在多条边.
- 伪图 (Pseudograph):
- 可以有环
- 可以有多重边
- 完全图 (Complete Graph): 表示为 , 具有 个顶点, 且每对不同的顶点之间都恰好有一条边相连.
- 二分图 (Bipartite Graph): 二分图的顶点被划分为两个不相交的集合, 和 . 每条边都连接 中的一个顶点和 中的一个顶点, 确保没有边连接同一集合内的顶点.
- 完全二分图 (Complete Bipartite Graph): 完全二分图, 表示为 , 其顶点集被划分为两个子集, 分别具有 和 个顶点. 当且仅当一个顶点属于第一个子集, 另一个顶点属于第二个子集时, 两个顶点之间才存在边.
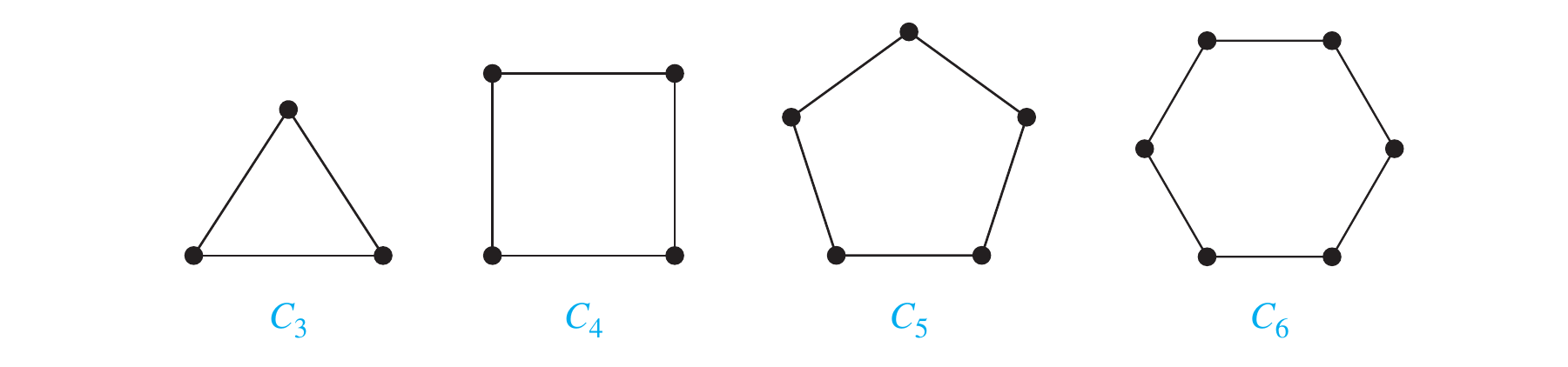
Cycles
A cycle , , consists of vertices and edges and .
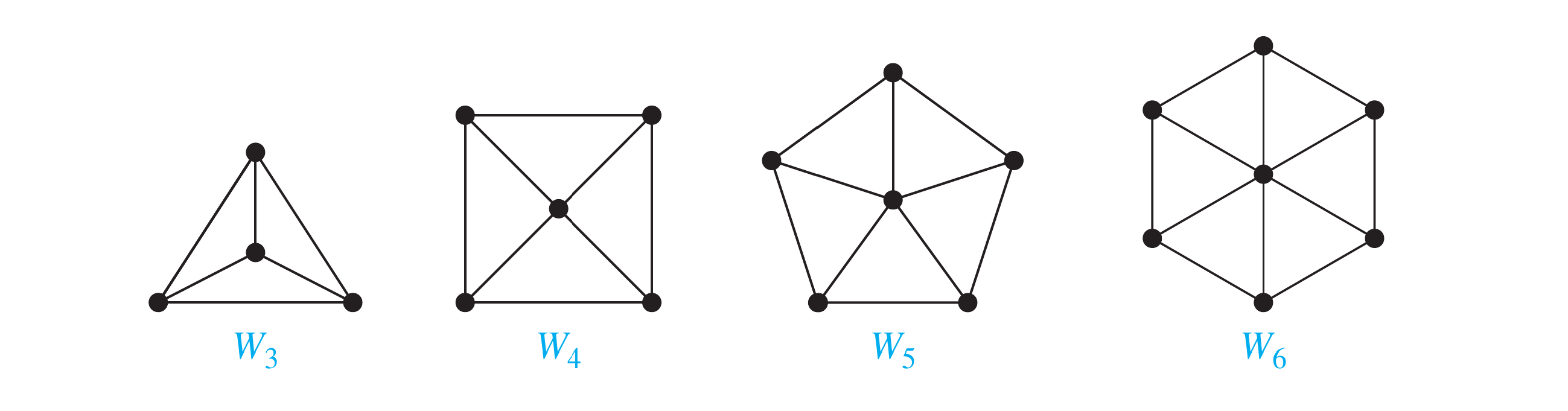
Wheels
We obtain a wheel when we add an additional vertex to a cycle , for , and connect this new vertex to each of the vertices in , by new edges.
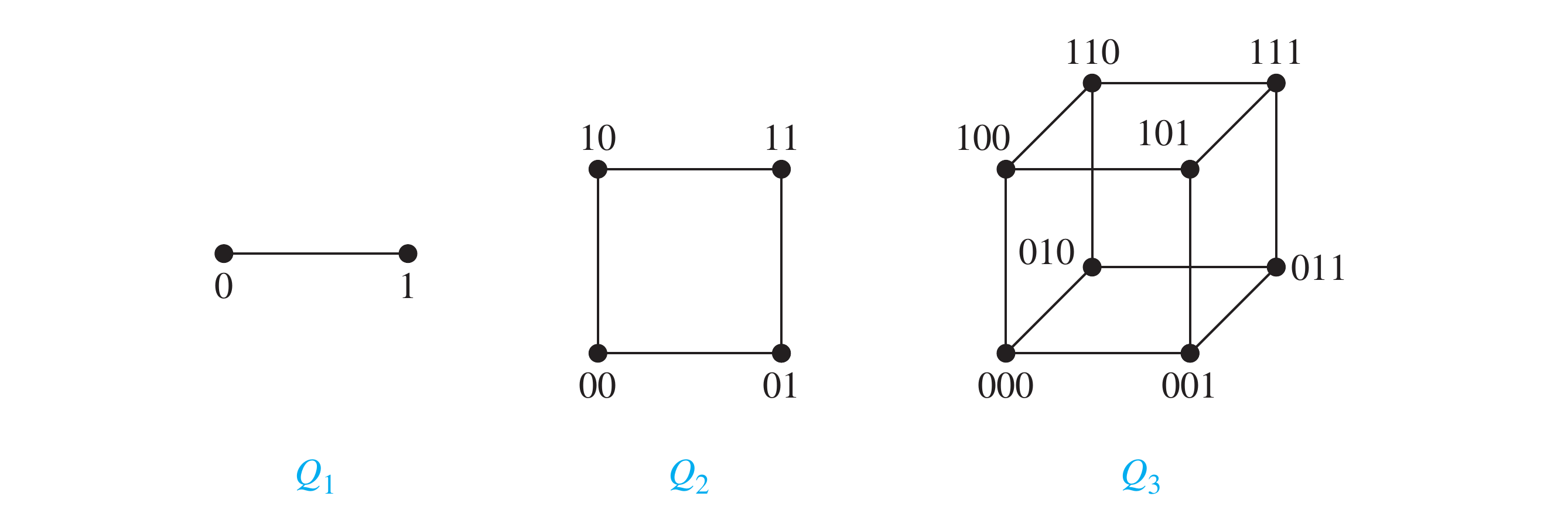
-Cubes
An -dimensional hypercube, or -cube, denoted by , is a graph that has vertices representing the bit strings of length . The vertices are adjacent if and only if the bit strings that they represent differ in exactly on bit position.
邻居和关联
- 邻居指点和点之间的关系
- 关联指点和边之间的关系
度
无向图
在无向图中, 顶点的度, 记为, 就是与其相连的边的数量. 但是, 一个顶点上的环对该顶点的度贡献两次.
有向图
在有向图中, 我们需要区分入边和出边:
- 顶点的入度, 记为, 是指以为终点的边的数量
- 顶点的出度, 记为, 是指以为起点的边的数量
就像在无向图中一样, 有向图中的环对它所在的顶点的入度和出度都贡献.
握手定理
设是一个有条边的无向图. 那么
换句话说, 无向图中所有顶点的度之和等于边数的两倍. 即使该图有多重边或环, 该定理也成立.
握手定理的一个关键推论是, 一个无向图总是具有偶数个奇数度的顶点.
二分图匹配
在一个简单图 = (, ) 中, 一个 匹配 是图的边集合 的一个子集, 其中任意两条边都没有公共顶点. 换句话说, 如果我们从一个匹配中选择两条不同的边, 那么它们四个端点必须是不同的顶点.
一个顶点如果是一个匹配 中某条边的端点, 则称该顶点是 已匹配的; 否则称为未匹配的.
一个 最大匹配 是指包含尽可能多边的匹配.
在二分图中, 从 到 的一个 完备匹配 是指一个匹配, 其中 中的每个顶点都是已匹配的. 这意味着匹配中的边的数量等于 中顶点的数量.
Hall婚姻定理
提供了一个判断是否存在完备匹配的关键条件:
一个具有二部划分 (, ) 的二分图 = (, ) 存在从 到 的完备匹配, 当且仅当 对于 的所有子集 , 都有 .
这里:
- 代表 的 邻域, 它是 中所有与 中至少一个顶点相邻的顶点的集合.
- 和 分别表示集合 和 中的元素(顶点)的数量.
简单来说, 如果 中任何顶点的子集, 其在 中的邻居数量都至少和该子集中的顶点数量一样多, 那么就存在一个完备匹配.
想象在一场舞会, 男生想找自己喜欢的女生跳舞:
- 如果有一群男生发现, 他们喜欢的女生总共比他们的人数还少, 那么肯定有男生要"被迫"落单, 也就是无法找到完备匹配.
- 但是, 如果任意一群男生喜欢的女生都至少等于他们的人数, 那么我们就可以合理安排, 让每个男生都找到舞伴, 并且没有重复的舞伴, 也就是能找到完备匹配.
Hall婚姻定理背后的直观思想是: 潜在的"资源"必须充足, 才能保证每个个体都被满足. 只有当每个子集都有足够多的邻居时, 才能确保整个集合存在完备匹配.
子图
在图论中, 图 的子图是指一个图 , 其中 是 的子集, 是 的子集. 如果 不等于 , 则 被认为是 的真子图.
有一种特殊的子图叫做诱导子图.
- 点诱导子图选定原图的顶点子集, 然后保留原图中连接这些顶点的所有边
- 边诱导子图通过选定原图的边子集, 然后包含这些边以及他们对应的端点
对点和边的操作
删点
从图中移除一个指定的顶点以及所有与该顶点相连的边
删边
从图中移除一条指定的边
收缩边
将一条边的两个端点合并成一个新顶点, 同时保留其他边(适当地连接到新顶点).
给定图 和边 , 收缩边 将 和 合并为一个新顶点 , 所有原来和 或 相连的边现在都连接到 .
细分边
在一条边中插入一个新的顶点, 将原来的边变成两条新的边.
图合并
将两个或多个图组合成一个新的图 给定两个图 和 , 它们的并集(或不相交并集, 取决于是否允许共享顶点和边)生成一个新图 , 其中 , . 如果两个图有相同的顶点, 则会保留这些相同的顶点.
图的表示
邻接列表
通过列出每个顶点以及其对应的相邻顶点来表示图. 例如:
| 顶点 (Vertex) | 相邻顶点 (Adjacent Vertices) |
|---|---|
邻接矩阵
关联矩阵
关联矩阵使用矩阵来表示图, 其中行表示顶点, 列表示边. 矩阵中的元素表示顶点是否关联到边.
关联矩阵还可以表示多重边和环. 多重边在矩阵中对应列的条目是相同的, 因为它们与相同的顶点对相关联.
在关联矩阵中, 每一个列只能有两个, 或者一个(环的情况). 如果两个列相同, 那么它们就对应于两个多重边.
图的同构
如果两个简单图之间存在一个一一对应的关系, 使得在一个图中相邻的两个顶点在另一个图中对应的顶点也相邻, 反之亦然, 那么这两个图就是同构的 (isomorphic).
也就是我能构造一个的双射, 使得图的结构保持不变.
要判断两个图是否同构, 可以考虑以下不变的性质:
- 顶点的数量
- 边的数量
- 每个度的顶点的数量
- 存在特定长度的简单环(回路) 如果两个图在以上任何一个性质上不同, 那么这两个图就不是同构的.
或者可以考虑
- 它们的补图同构吗
连通性
连通性、路径和回路
路径是连接一系列顶点的边的序列, 回路是一条起点和终点相同的路径. 如果路径或回路不包含重复的边, 则称其为简单的.
注意区别回路和环, 在这门课的语境下
- 回路是一条起点和终点相同的路径
- 环, 即自环, 是自己连向自己的一条边
如果一个无向图中任意两个不同的顶点之间都存在路径, 则称该无向图是连通的. 相反, 如果至少存在一对顶点之间没有连接路径, 则称该图是不连通的.
在连通的无向图中, 任意两个不同的顶点之间总是存在一条简单路径
连通分量是一个最大的连通子图, 意思是
- 它是原图的一个子图
- 它是连通的
- 它不属于任何一个更大的连通子图
一个不连通的图将有两个或更多的连通分量
割点、割边和连通度
割点, 也称为关节点, 是指删除后会使图不连通的顶点. 割边或桥是指删除后会导致图的连通分量增加的边.
对于非完全图, 顶点连通度, 记为, 是指为使图不连通需要删除的最小顶点数. 如果一个图的顶点连通度大于等于, 则称该图是 -连通的.
也就是说, 如果一个图是-连通的, 那么它必然也是-连通的.
边连通度, 记为, 定义为具有多个顶点的连通图中, 为使图不连通必须删除的最小边数.
顶点连通度和边连通度之间存在以下不等式关系:
这表示顶点连通度小于等于边连通度, 边连通度小于等于图中任意顶点的最小度数.
有向图中的连通性
有向图引入了强连通和弱连通的概念. 如果对于图中的每一对顶点, 都存在从顶点 到顶点 的路径, 且存在从顶点 到顶点 的路径, 则称有向图是强连通的. 如果忽略边的方向后, 任意两个顶点之间都存在路径, 则称有向图是弱连通的.
强连通分量 是有向图中最大的强连通子图. 有向图中的任意两个顶点要么在同一个强连通分量中, 要么在不相交的强连通分量中.
欧拉路径, 欧拉回路和哈密顿回路
欧拉回路 (Euler Circuit)
在一个图 中, 欧拉回路是一条简单回路, 它包含图 G 的每一条边.
可以想象成一笔画问题, 你要用笔不重复地画完所有线条, 并且最后回到起点.
对于连通无向图而言, 存在欧拉回路的充要条件是, 每个点的度都是偶数.
对于一个强连通的有向图而言, 存在欧拉回路的充要条件是, 每个点的出度等于入度.
如何寻找欧拉回路?
- 不断地找环
- 然后在环与环之间的交点上把它们连接起来
欧拉路径 (Euler Path)
在一个图 中, 欧拉路径是一条简单路径, 它包含图 G 的每一条边.
还是想象成一笔画问题, 你要用笔不重复地画完所有线条, 但最后不一定要回到起点.
对于连通无向图而言, 存在欧拉回路的充要条件是, 每个点的度都是偶数, 或者有且仅有两个点有奇数的度数.
对于弱连通有向图(忽略边的方向并将其视为所有顶点之间都存在路径), 存在欧拉路径的充要条件是满足以下两种情况之一:
- 每个顶点的入度等于出度, 这意味着它也具有欧拉回路.
- 恰好存在一个顶点
出度 = 入度 + 1(起始顶点), 且恰好存在一个顶点的入度 = 出度 + 1(结束顶点), 且所有其他顶点的入度等于出度.
如何寻找欧拉路径?
- 如果有奇度点, 就从奇度点开始找.
哈密顿回路 (Hamilton Circuit)
在一个图 中, 哈密顿回路是一条简单回路, 它经过图 G 的每一个顶点恰好一次.
哈密顿回路的必要条件
-
狄拉克定理 (Dirac's Theorem): 如果一个图有 个顶点, 且 , 并且每个顶点的度 (连接到该顶点的边的数量) 都至少是 , 那么这个图就存在哈密顿回路. 换句话说, 如果图中每个顶点都与至少一半的其他顶点相邻, 那么这个图中就一定能找到一条访问所有顶点一次的回路.
-
奥尔定理 (Ore's Theorem): 如果一个图有 个顶点, 且 , 并且对于每一对不相邻的顶点 和 , 它们的度之和大于等于 , 那么这个图就存在哈密顿回路. 这个定理表明, 如果图中任何两个不相邻的顶点他们的度之和足够大的话, 也能够保证图中存在哈密顿回路.
总结与比较:
- 欧拉回路/路径 关注的是边, 要求遍历所有边且只遍历一次.
- 哈密顿回路 关注的是顶点, 要求遍历所有顶点且只遍历一次.
- 欧拉回路/路径和哈密顿回路/路径并不互相保证: 一个图有欧拉回路不代表有哈密顿回路, 反之亦然.
- 图中可能存在多个欧拉回路/路径或哈密顿回路.
中国邮递员问题(Chinese Postman Problem, CPP)
找到一条图中回路, 这条回路能够遍历图中的每一条边至少一次, 并且路径的总长度最短,
- 如果图中存在欧拉回路, 那么这就是最优路线, 并且路径的总长度就是图中所有边的权重之和
- 如果图中不存在欧拉回路,
平面图
一个平面图是一个可以在平面上绘制的图, 并且没有任何边会交叉. 更正式地说, 如果一个图可以嵌入在平面中(等价于可以嵌入一个球面), 那么这个图就是平面的, 这意味着每个顶点都映射到平面上不同的点, 并且每条边都映射到一条连续的曲线. 代表边的曲线除了可能在它们的端点(顶点)相交外, 不能相交.
欧拉公式指出, 对于任何连通的平面图, 顶点数 () 减去边数 () 加上区域数 () 等于 :
注意欧拉公式是不能用来判断平面图, 因为除非我们已经把图画在一个平面上, 否则就没有区域的概念了.
可以通过这样一种方式来记忆欧拉公式
- 如果给平面图添加一个顶点并连一条边到原来的图上, 则分别的变化量为. 要使总的变化量不变, 故和的符号必然相反
- 如果给平面图未连接的两个顶点加上一条新边, 则分别的变化量为, 要使总得变化量不变, 故和的符号也必然相反.
欧拉公式可以用来推导出平面图必须满足的不等式(必要条件). 例如:
- 在一个至少有 个顶点的简单平面图中, .
- 在一个至少有 个顶点, 且没有长度为的回路的简单平面图中, .
- 每个连通的简单平面图至少有一个顶点的度数小于或等于 .
Kuratowski定理提供了一种确定图是否是平面图的方法(充要条件). 这个定理指出, 一个图是平面图当且仅当它不包含一个子图, 该子图是 (5 个顶点的完全图) 或 (两个各有 3 个顶点的完全二分图) 的细分.
一个图的细分是通过用包含一个或多个顶点的路径替换原始图中的边而得到的图.
图的着色
顶点着色数
图着色是指给图的每个顶点分配一种颜色, 使得任何两个相邻的顶点都被分配不同的颜色. 一个图的色数是给这个图着色所需的最少颜色数. 图 的色数记为 .
四色定理指出, 平面图的色数不大于.
当且仅当可以将两种不同的颜色分配给图的每个顶点, 使得任何两个相邻的顶点被分配不同的颜色时, 一个简单图才是二分图. 这意味着二分图的色数为 .
更精确的色数界限:
- 表示图 G 中最大团(clique)的大小, 也就是图中最大的完全子图的顶点数. 是色数的下限, 因为最大团里的所有顶点都需要不同的颜色.
- 表示图 G 中顶点的最大度(maximum degree), 即与一个顶点相连的最大的边的数量. 是色数的上限. 表明一个贪心算法最多需要 种颜色完成着色.
边着色数
与顶点着色不同, 边着色是指给图的每条边分配一种颜色, 使得任何两条共享同一个顶点的边都被分配不同的颜色. 一个图的边着色数通常用 表示, 是给这个图进行边着色所需的最少颜色数.
Vizing 定理
或者
对于任何图, Vizing 定理表明其边色数 只能是 或者 . 也就是说一个图的边色数要么等于它的最大度, 要么等于它的最大度加一.
树
树的内点就是有孩子的顶点 如果叉树的每一个内点都恰好有个孩子, 则我们称它们满叉树
树的高度定义如下
- 空树的高度为
- 只有一个根节点的树的高度为
满叉树
一棵完全叉树是其中每个树叶都在同一层上的满叉树 带有个内点的满叉树含有个顶点
- 因为除了根之外的每个顶点都是内点的孩子 带有个内点的满叉树含有个树叶
- 总边数等于内节点数乘以, 即
- 总顶点数等于总边数加, 即
- 总顶点数等于内点数加上树叶数
- 所以
平衡叉树
若一颗高度为的叉树的所有树叶都在或者层, 则这棵树是平衡的
哈夫曼编码
核心思想: 频率高的符号使用较短的编码, 频率低的符号使用较长的编码 是一种前缀码: 没有任何一个编码是其他任何编码的前缀, 因此解码时不会有歧义
构造哈夫曼树
- 构建最小堆: 将所有节点插入到一个最小堆(优先队列)中, 最小堆的比较标准是节点的频数. 频数低的节点排在前面.
- 合并节点:
- 从最小堆中取出两个频数最小的节点.
- 创建一个新的父节点, 其频数为这两个节点频数之和.
- 将两个取出节点设为新父节点的左孩子和右孩子(左右孩子的顺序并不影响最终结果).
- 将新父节点插入回最小堆中.
- 重复合并: 重复步骤 3, 直到最小堆中只剩下一个节点, 这个节点就是哈夫曼树的根节点.
- 生成编码: 从根节点开始, 遍历哈夫曼树:
- 左分支用 '0' 表示.
- 右分支用 '1' 表示.
- 从根节点到每个叶节点的路径上的 '0' 和 '1' 组成的字符串, 就是对应字符的哈夫曼编码
有序根树
地址 (即路径表示)
根节点为, 表示为如 等, 代表每一层选择了第几个孩子
最小生成树
Prim
Prim算法的主要思想是通过迭代地添加连接最小生成树中一个顶点和不在最小生成树中的顶点的最小权重边, 来构造一个加权无向图的最小生成树. 简单来说, 它从任意一个顶点开始, 通过始终连接到最近的可用的顶点来贪婪地扩展树.
Kruskal
Kruskal算法的主要思想是按照边的权重从小到大的顺序依次考虑图中的所有边. 如果当前考虑的边连接的两个顶点属于不同的连通分量, 就将这条边添加到最小生成树中, 并将这两个连通分量合并为一个. 重复这个过程, 直到所有顶点都属于同一个连通分量, 此时所选的边就构成了最小生成树. 简单来说, Kruskal 从权重最小的边开始, 逐步构建最小生成树, 并且避免形成环路.