Progressive Distillation Method
Idea
The core idea involves a distillation process where a pre-trained "teacher" model, which requires a high number of sampling steps (up to 8192), is used to train a "student" model that takes significantly fewer steps. This distillation is progressively applied, effectively halving the number of required sampling steps at each iteration. Remarkably, this approach allows for models that can generate samples in as few as 4 steps while still maintaining high perceptual quality
Method
Require:
- Trained teacher model
- Data set
- Loss weight function
- Student sampling steps
For iterations do
- ⟶ Init student from teacher
While not converged do
- 2 steps of DDIM with teacher
- ⟶ Teacher target
- End while
- ⟶ Student becomes next teacher
- ⟶ Halve number of sampling steps End for
Where the target is set to such that if we use the student model to sample DDIM step from using the mean determined by (with zero variance in DDIM), then the denoised result should equal to , which the the denoised result of the teacher model after DDIM steps with the mean determined by
New parameterization method: v-prediction
Idea
The authors proposed an alternative method of v-prediction, which involves predicting a latent variable instead of directly predicting the noise . This approach provides more stable training dynamics, particularly when distilling diffusion models to fewer steps. The relationship between and is defined through the following key ideas:
- is a transformation of both the original data and the noise.
- By predicting , the model can smoothly transition between steps, allowing it to interpolate between predicting the noise directly and predicting the clean data.
Formulation
For two times , we want to update from to (), and the update rule given by DDIM is
We can simplify the DDIM update rule by expressing it in terms of . Assuming a variance preserving diffusion process, we have , and hence
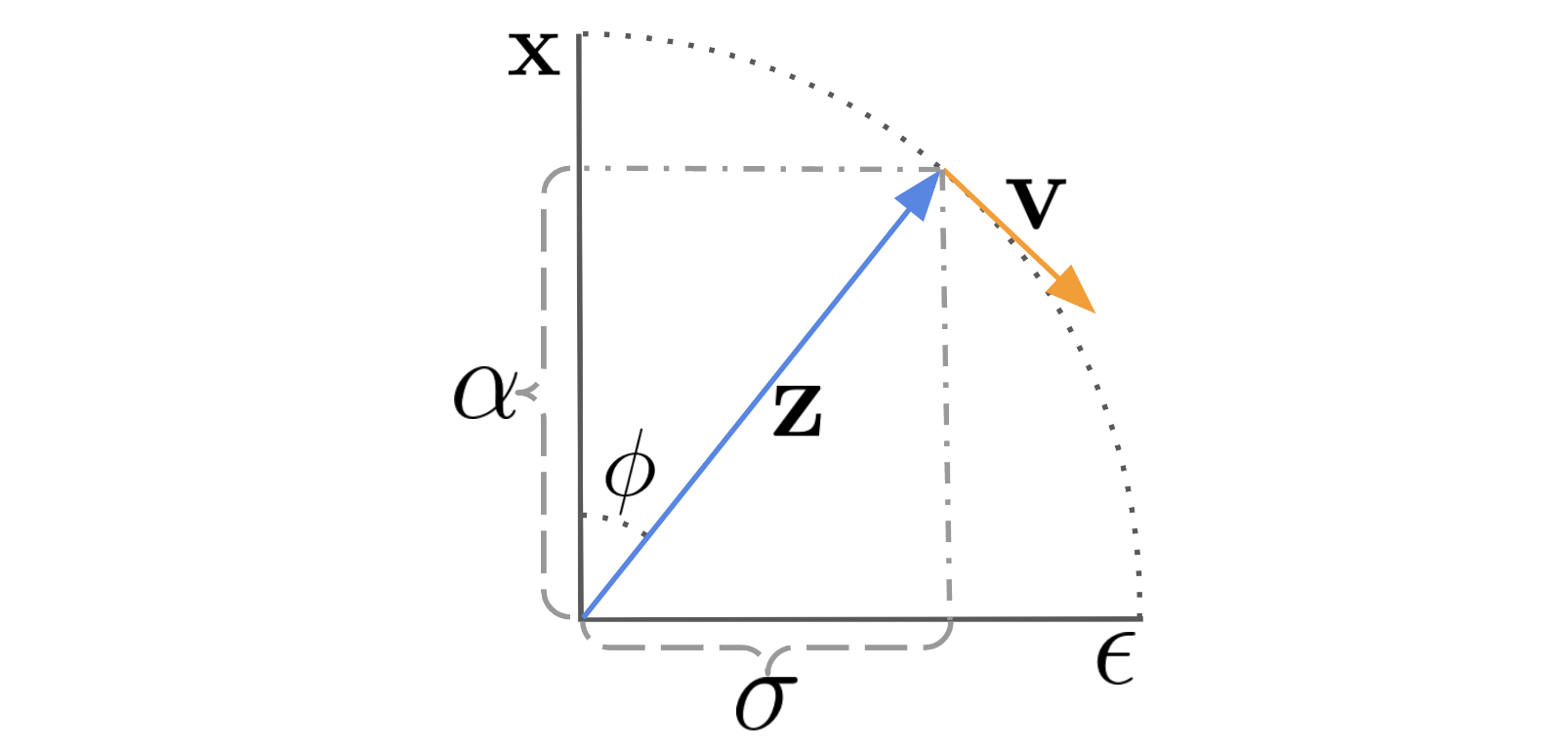
And we define the velocity of
Furthermore, we define the predicted velocity as
where . And now we have
Viewed from this perspective, DDIM thus evolves by moving it on a circle in the basis, along the direction, gradually denoising smoothly towards