Motivation
Architecture
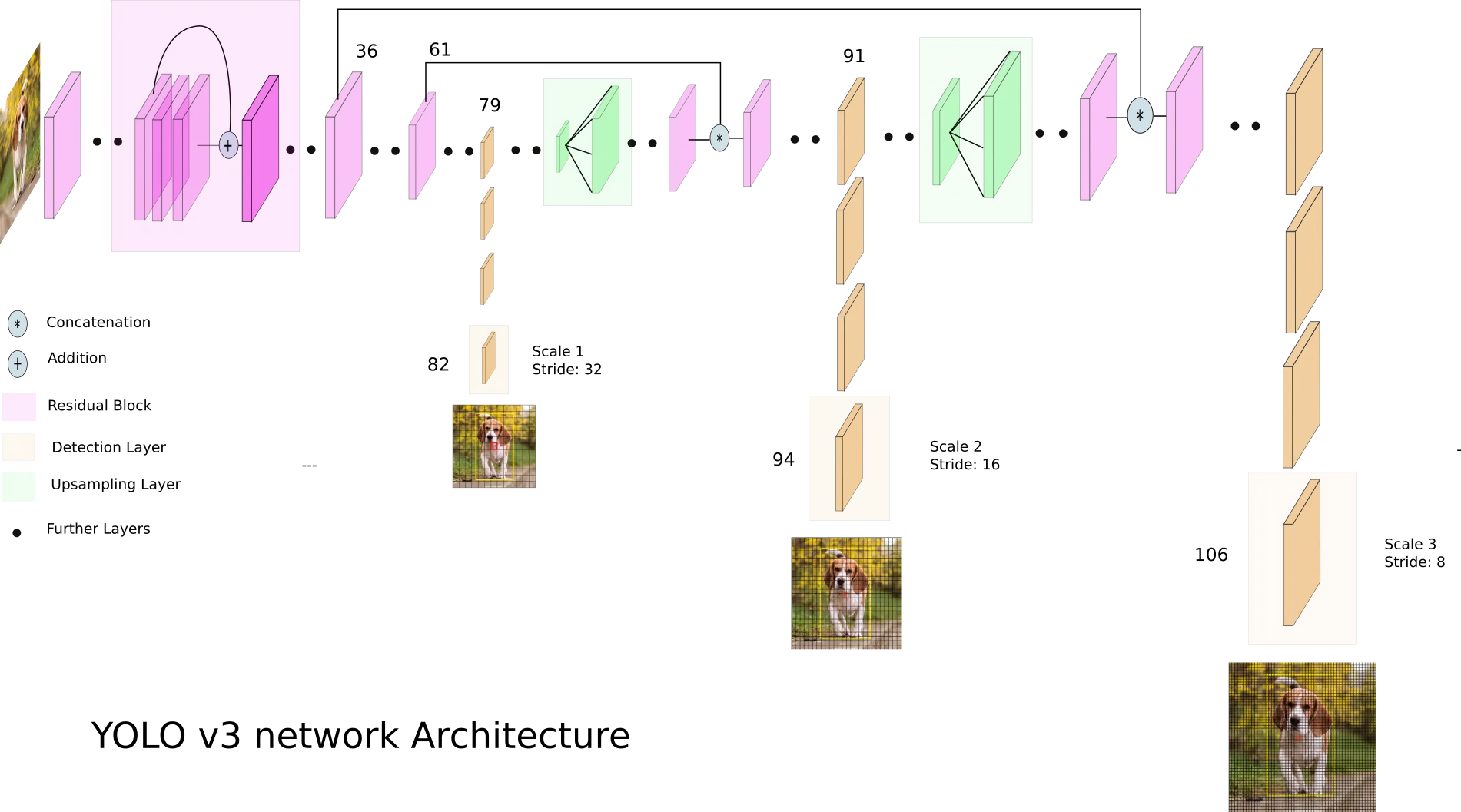 YOLOv3 makes detections at 3 different places in the network. These are layers 82nd, 94th and 106th layer.
YOLOv3 makes detections at 3 different places in the network. These are layers 82nd, 94th and 106th layer.
- Network Input
- For nd layer the stride is and the output size is and it is responsible to detect large objects
- For th layer the stride is and the output size is and it is responsible to detect medium objects
- For nd layer the stride is and the output size is and it is responsible to detect small objects
To produce outputs YOLO v3 applies kernels at three output layers in the network. The shape of the kernels has its depth that is calculated by , where is the number of bonding boxes, and is the number of classes for COCO dataset. Therefore, the depth is , and the shapes of these output feature maps are
Box Generation
Anchor Boxes is used to predict bounding boxes. YOLO v3 uses predefined bounding boxes to calculate real width and real height for predicted bounding boxes.
In total anchor boxes are used, anchor boxes for each scale. This means at each output layer every grid scale of feature map can predict bounding boxes using anchor boxes.
To calculate these anchor, YOLO v3 uses -means clustering as in YOLO v2
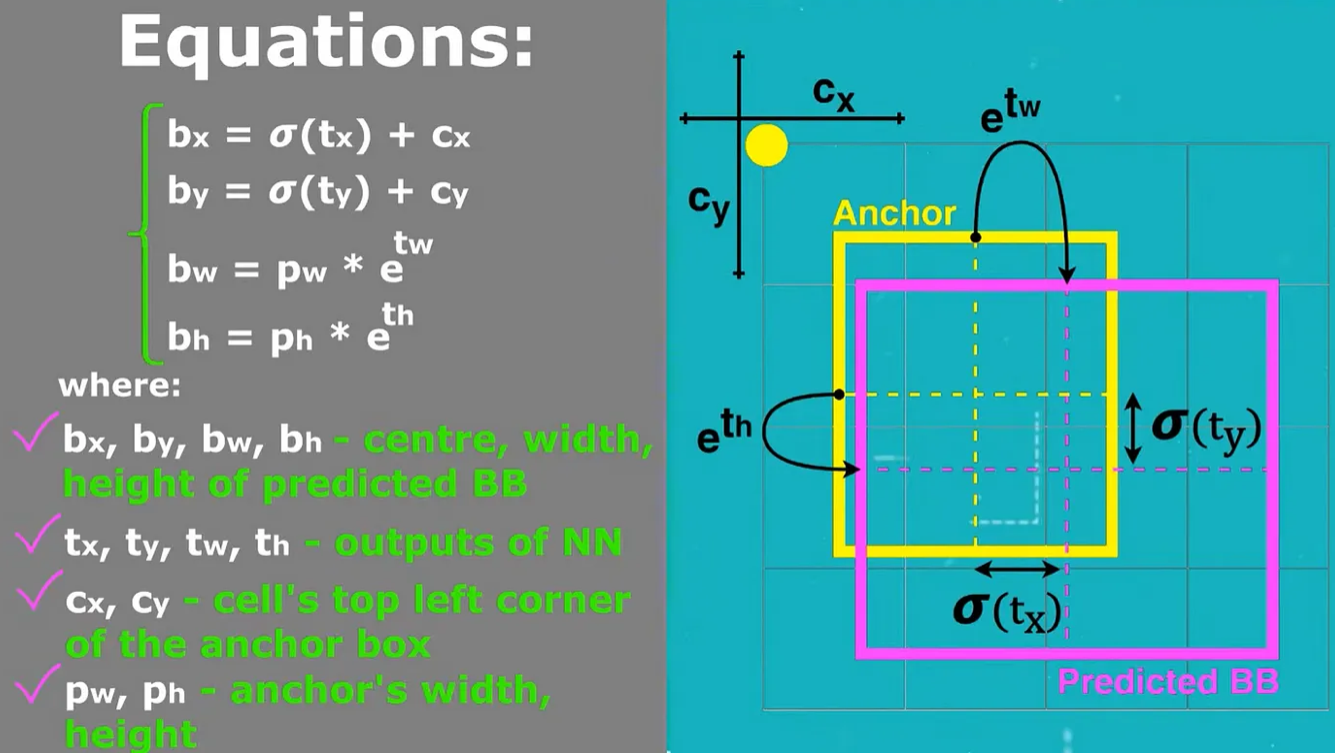
- To predict center coordinates of bounding boxes , YOLO v3 passes outputs through sigmoid function
- Then based on the above equations given in figure we get center coordinates and width and height of the bounding boxes.
- All the redundant bounding boxes are suppressed using Non-maximum Suppression