Preliminaries on Partial Derivatives
Suppose a scalar variable depend on some variables , we write as the partial derivatives of . We stress that the convention here is that has exactly the same dimension as itself. For example, if , then , and the -entry of is equal to .
Chain rule
Consider a scalar variable which is obtained by the composition of and on some variable
Let and let , then the standard chain rule gives us that
or in a vectorized notation
In other words, the backward function is always a linear map from to .
Key interpretation of the chain rule
We can view the formula above as a way to compute from
Moreover, this formula only involves knowledge about (more precisely ).
We use to define the function that maps to , and write
We call the backward function for the module . Note that when is fixed, is merely a linear map from to
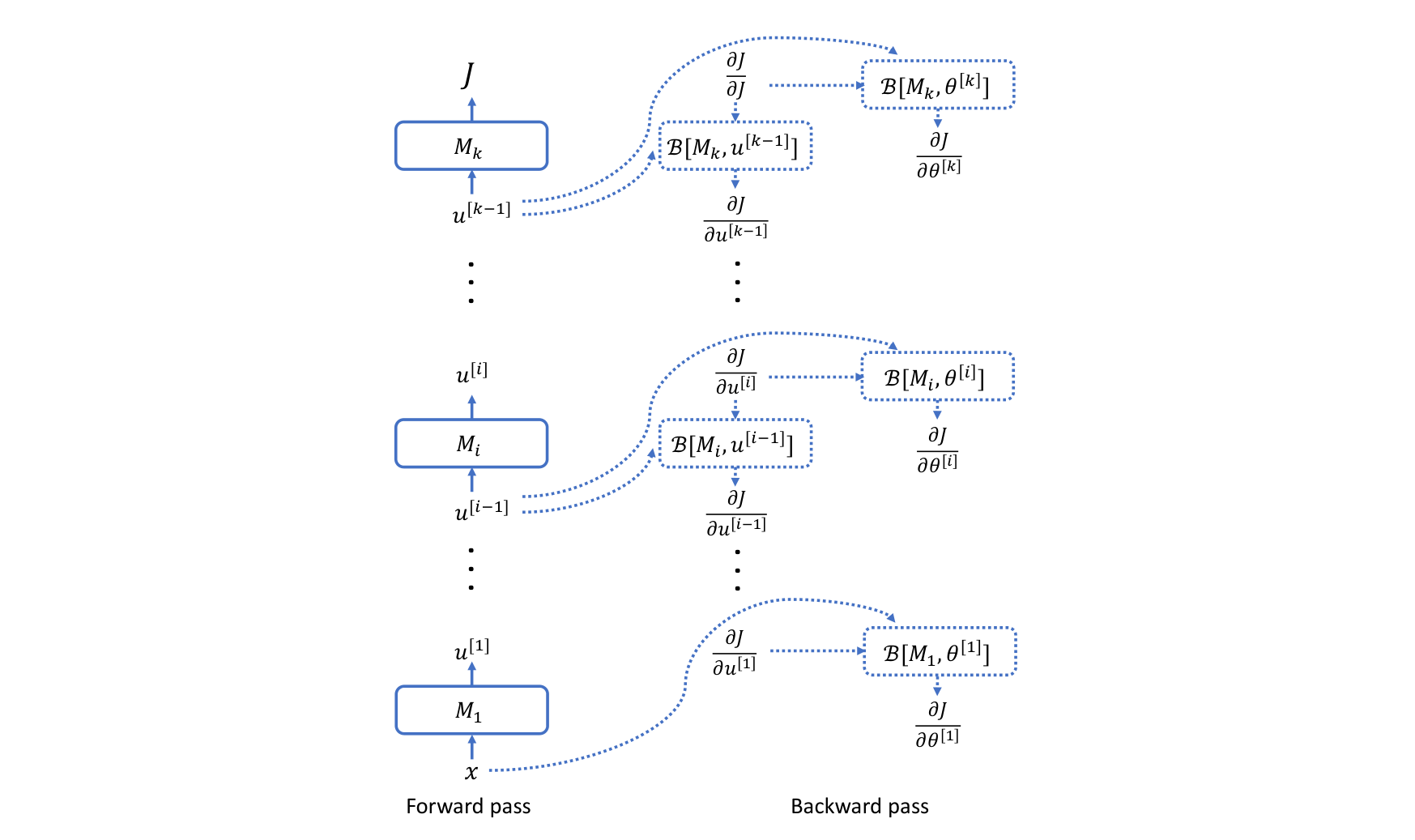
General strategy of back-propagation
We take the viewpoint that neural networks are complex compositions of small building blocks such as MM, , Conv2D, LN etc., then we can abstractly write the loss function (on a single example ) as a composition of many modules
We assume that each involves a set of parameters , though could possibly be an empty set when is a fixed operation such as the non-linear activations.
We introduce the intermediate variables for the composition
Back-propagation consists of two passes. In the forward pass, the algorithm simply computes from , and save all the intermediate variables 's in the memory.
In the backward pass, we first compute the derivatives w.r.t to the intermediate variables, that is, , sequentially in this backward order, and then compute the derivatives of the parameters form and . These two type of computations can be also interleaved with each other because only depends on and .
We first see why can be computed efficiently from and by invoking the discussion on the chain rule. We instantiate the discussion by setting and , and , and . Note that is very complex but we don't need any concrete information about . Then, the conclusive equation corresponds to
More precisely, we can write
Instantiating the chain rule with and , we also have
Example Code
#include <vector>
#include <memory>
// Base class for a module
class Module {
public:
virtual ~Module() = default;
// Forward pass: computes output given input
virtual std::vector<double> forward(const std::vector<double>& input) = 0;
// Backward pass: computes gradients of input and parameters
virtual std::vector<double> backward(const std::vector<double>& grad_output) = 0;
// Update parameters using gradients
virtual void update_parameters(double learning_rate) = 0;
};
// Neural network class
class NeuralNetwork {
private:
std::vector<std::shared_ptr<Module>> modules;
std::vector<std::vector<double>> intermediate_outputs;
public:
void add_module(std::shared_ptr<Module> module) {
modules.push_back(module);
}
// Forward pass
std::vector<double> forward(const std::vector<double>& input) {
intermediate_outputs.clear();
std::vector<double> current_output = input;
intermediate_outputs.push_back(current_output); // Save input
for (const auto& module : modules) {
current_output = module->forward(current_output);
intermediate_outputs.push_back(current_output); // Save intermediate output
}
return current_output; // Final output (loss)
}
// Backward pass
void backward(const std::vector<double>& grad_loss) {
std::vector<double> current_grad = grad_loss;
for (int i = modules.size() - 1; i >= 0; --i) {
current_grad = modules[i]->backward(current_grad);
}
}
// Update parameters
void update_parameters(double learning_rate) {
for (const auto& module : modules) {
module->update_parameters(learning_rate);
}
}
};
// Example usage
int main() {
NeuralNetwork network;
// Add modules to the network (e.g., Linear, ReLU, etc.)
// network.add_module(std::make_shared<Linear>(...));
// network.add_module(std::make_shared<ReLU>());
// Forward pass
std::vector<double> input = { /* input data */ };
std::vector<double> output = network.forward(input);
// Compute loss gradient (e.g., using a loss function)
std::vector<double> grad_loss = { /* gradient of loss w.r.t. output */ };
// Backward pass
network.backward(grad_loss);
// Update parameters
double learning_rate = 0.01;
network.update_parameters(learning_rate);
return 0;
}
#include <vector>
#include <memory>
#include <random>
#include <iostream>
#include <stdexcept>
class Linear : public Module {
private:
std::vector<std::vector<double>> weights; // Weight matrix (W)
std::vector<double> bias; // Bias vector (b)
std::vector<double> input; // Saved input for backward pass
std::vector<std::vector<double>> grad_weights; // Gradient of weights
std::vector<double> grad_bias; // Gradient of bias
public:
// Constructor: Initializes weights and biases randomly
Linear(int input_size, int output_size) {
// Initialize weights and biases with random values
std::random_device rd;
std::mt19937 gen(rd());
std::normal_distribution<double> dist(0.0, 0.01);
weights.resize(output_size, std::vector<double>(input_size));
for (int i = 0; i < output_size; ++i) {
for (int j = 0; j < input_size; ++j) {
weights[i][j] = dist(gen);
}
}
bias.resize(output_size);
for (int i = 0; i < output_size; ++i) {
bias[i] = dist(gen);
}
// Initialize gradients to zero
grad_weights.resize(output_size, std::vector<double>(input_size, 0.0));
grad_bias.resize(output_size, 0.0);
}
// Forward pass: Computes y = Wx + b
std::vector<double> forward(const std::vector<double>& input) override {
if (input.size() != weights[0].size()) {
throw std::invalid_argument("Input size does not match weight matrix dimensions.");
}
this->input = input; // Save input for backward pass
std::vector<double> output(weights.size(), 0.0);
for (int i = 0; i < weights.size(); ++i) {
for (int j = 0; j < input.size(); ++j) {
output[i] += weights[i][j] * input[j];
}
output[i] += bias[i];
}
return output;
}
// Backward pass: Computes gradients of input, weights, and bias
std::vector<double> backward(const std::vector<double>& grad_output) override {
if (grad_output.size() != weights.size()) {
throw std::invalid_argument("Gradient output size does not match weight matrix dimensions.");
}
std::vector<double> grad_input(weights[0].size(), 0.0);
// Compute gradient of input
for (int j = 0; j < weights[0].size(); ++j) {
for (int i = 0; i < weights.size(); ++i) {
grad_input[j] += weights[i][j] * grad_output[i];
}
}
// Compute gradient of weights
for (int i = 0; i < weights.size(); ++i) {
for (int j = 0; j < weights[0].size(); ++j) {
grad_weights[i][j] += grad_output[i] * input[j];
}
}
// Compute gradient of bias
for (int i = 0; i < weights.size(); ++i) {
grad_bias[i] += grad_output[i];
}
return grad_input;
}
// Update parameters using gradients and learning rate
void update_parameters(double learning_rate) override {
for (int i = 0; i < weights.size(); ++i) {
for (int j = 0; j < weights[0].size(); ++j) {
weights[i][j] -= learning_rate * grad_weights[i][j];
}
}
for (int i = 0; i < bias.size(); ++i) {
bias[i] -= learning_rate * grad_bias[i];
}
// Reset gradients to zero
for (int i = 0; i < weights.size(); ++i) {
for (int j = 0; j < weights[0].size(); ++j) {
grad_weights[i][j] = 0.0;
}
}
for (int i = 0; i < bias.size(); ++i) {
grad_bias[i] = 0.0;
}
}
// Utility function to print weights and biases
void print_parameters() const {
std::cout << "Weights:" << std::endl;
for (const auto& row : weights) {
for (double val : row) {
std::cout << val << " ";
}
std::cout << std::endl;
}
std::cout << "Biases:" << std::endl;
for (double val : bias) {
std::cout << val << " ";
}
std::cout << std::endl;
}
};
// Example usage
int main() {
Linear linear_layer(3, 2); // Input size = 3, Output size = 2
std::vector<double> input = {1.0, 2.0, 3.0};
// Forward pass
std::vector<double> output = linear_layer.forward(input);
std::cout << "Output:" << std::endl;
for (double val : output) {
std::cout << val << " ";
}
std::cout << std::endl;
// Backward pass (dummy gradient)
std::vector<double> grad_output = {0.1, 0.2};
linear_layer.backward(grad_output);
// Update parameters
linear_layer.update_parameters(0.01);
// Print updated parameters
linear_layer.print_parameters();
return 0;
}