Classifier
For parameters , write our classifier as
Here, if , and otherwise.
Note
A bigger indicates a more confident prediction.
Functional Margin
Given a training example , we define the functional margin of as
Note that if , then for the functional margin to be large (i.e., for our prediction to be confident and correct), we need to be a large positive number. Conversely, if , then for the functional margin to be large, we need to be a large negative number. Moreover, if , then our prediction on this example is correct. Hence, a large functional margin represents a confident and a correct prediction.
Given a training set , we also define the function margin of with respect to as the smallest of the functional margins of the individual training examples. Denoted by , this can therefore be written:
Issues with this form
For a linear classifier with the choice of given above (taking values in ), there's one property of the functional margin that makes it not a very good measure of confidence. Given our choice of , we note that if we replace with and with , then since , this would not change at all. However, replacing with also results in multiplying our functional margin by a factor of . Thus, it seems that by exploiting our freedom to scale and , we can make the functional margin arbitrarily large without really changing anything meaningful. Intuitively, it might therefore make sense to impose some sort of normalization condition such as that ; i.e., we might replace with , and instead consider the functional margin of .
Geometric Margin
Consider the picture below
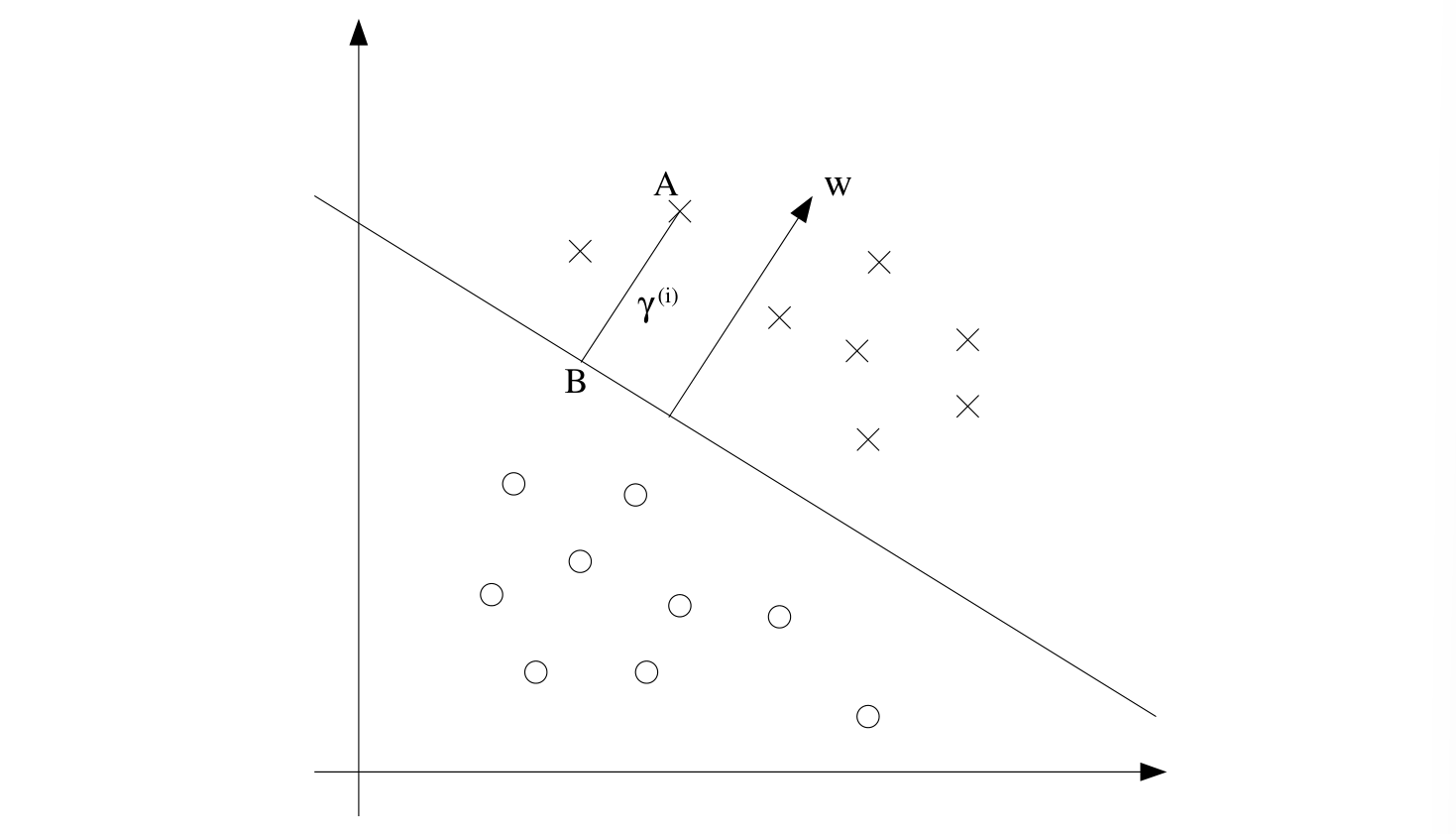
The decision boundary corresponding to is shown, along with the vector . Note that is orthogonal (at 90°) to the separating hyperplane. Consider the point at A, which represents the input of some training example with label . Its distance to the decision boundary, , is given by the line segment AB.
Since is on the decision boundary , we have
Solving for yields
More generally, we define the geometric margin of with respect to a training example to be
Note that if , then the functional margin equals the geometric margin.
The Optimal Margin Classifier
Note
For now, we will assume that we are given a training set that is linearly separable.
Form 1
To maximize the geometric margin, we could pose the following optimization problem
If we could solve the optimization problem above, we'd be done. But the "" constraint is a nasty (non-convex) one, and this problem certainly isn't in any format that we can plug into standard optimization software to solve.
Form 2
So, let's try transforming the problem into a nicer one. Consider:
Here, we're going to maximize , subject to the functional margins all being at least . Since the geometric and functional margins are related by , this will give us the answer we want. Moreover, we've gotten rid of the constraint that we didn't like. The downside is that we now have a nasty (again, non-convex) objective function.
Form 3
Recall our earlier discussion that we can add an arbitrary scaling constraint on and without changing anything. Therefore, we introduce the scaling constraint that the functional margin of with respect to the training set must be :
This restriction can be satisfied by rescaling . Noting that maximizing is the same thing minimizing , we now have the following optimization problem:
We've now transformed the problem into a form that can be efficiently solved.
Lagrange Duality
Primal Problem
Consider the following, which we'll call the primal optimization problem:
To solve it, we start by defining the generalized Lagrangian
Here, the 's and 's are the Lagrange multipliers. Consider the quantity
Here, the "" subscript stands for "primal." Let some be given. If violates any of the primal constraints (i.e., if either or for some ), then you should be able to verify that
Conversely, if the constraints are indeed satisfied for a particular value of , then . Hence,
Thus, takes the same value as the objective in our problem for all values of w that satisfies the primal constraints, and is positive infinity if the constraints are violated. Hence, if we consider the minimization problem
we see that it is the same problem (i.e., and has the same solutions as) our original, primal problem. For later use, we also define the optimal value of the objective to be ; we call this the value of the primal problem.
Dual Problem
Now, let's look at a slightly different problem. We define
Here, the "" subscript stands for "dual." Note also that whereas in the definition of we were optimizing (maximizing) with respect to , here we are minimizing with respect to .
We can now pose the dual optimization problem:
This is exactly the same as our primal problem shown above, except that the order of the "max" and the "min" are now exchanged. We also define the optimal value of the dual problem's objective to be .
How are the primal and the dual problems related? It can easily be shown that this follows from the "max min" of a function always being less than or equal to the "min max." However, under certain conditions, we will have
so that we can solve the dual problem in lieu of the primal problem.
Karush-Kuhn-Tucker (KKT) conditions
Assumptions Suppose and the 's are convex, and the 's are affine (i.e. there exists so that ). Suppose further that constraints are (strictly) feasible (i.e. there exists some so that for all ).
Claim There must exist so that is the solution to the primal problem, are the solution to the dual problem, and moreover .
and satisfy the Karush-Kuhn-Tucker (KKT) conditions:
The Dual Form of SVM
Support Vectors
Previously, we posed the following (primal) optimization problem for finding the optimal margin classifier
We can write the constraints as
We have one such constraint for each training example. Note that from the KKT dual complementarity condition, we will have only for the training examples that have functional margin exactly equal to one (i.e., the ones corresponding to constraints that hold with equality, ). Consider the figure below, in which a maximum margin separating hyperplane is shown by the solid line.
 The points with the smallest margins are exactly the ones closest to the decision boundary; here, these are the three points (one negative and two positive examples) that lie on the dashed lines parallel to the decision boundary. Thus, only three of the ’s—namely, the ones corresponding to these three training examples—will be non-zero at the optimal solution to our optimization problem. These three points are called the support vectors in this problem.
The points with the smallest margins are exactly the ones closest to the decision boundary; here, these are the three points (one negative and two positive examples) that lie on the dashed lines parallel to the decision boundary. Thus, only three of the ’s—namely, the ones corresponding to these three training examples—will be non-zero at the optimal solution to our optimization problem. These three points are called the support vectors in this problem.
Find the dual problem
Now we construct the Lagrangian for SVM, we have
Note that there're only "" but no "" Lagrange multipliers, since the problem has only inequality constraints. To find the dual form of the problem, we need to first minimize with respect to and (for fixed ), to get , via setting the derivatives of with respect to and to zero
Taking these results into the original Lagrangian
and
With , we get the final result
Putting this together with the constraints (that we always had) and the constraint of , we obtain the following dual optimization problem
Regularization and the Non-separable Case
The derivation of the SVM as presented so far assumed that the data is linearly separable. While mapping data to a high dimensional feature space via does generally increase the likelihood that the data is separable, we can't guarantee that it always will be so. Also, in some cases it is not clear that finding a separating hyperplane is exactly what we'd want to do, since that might be susceptible to outliers. For instance, the left figure below shows an optimal margin classifier, and when a single outlier is added in the upper-left region (right figure), it causes the decision boundary to make a dramatic swing, and the resulting classifier has a much smaller margin.
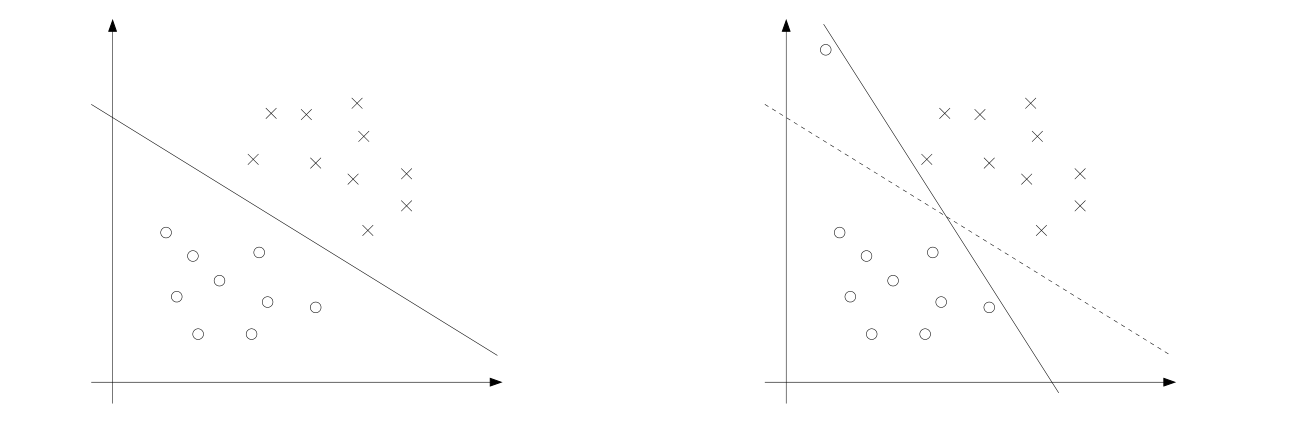 To make the algorithm work for non-linearly separable datasets as well as be less sensitive to outliers, we reformulate our optimization (using regularization) as follows:
To make the algorithm work for non-linearly separable datasets as well as be less sensitive to outliers, we reformulate our optimization (using regularization) as follows:
Thus, examples are now permitted to have (functional) margin less than , and if an example has functional margin (with ), we would pay a cost of the objective function being increased by . The parameter controls the relative weighting between the twin goals of making the small (which we saw earlier makes the margin large) and of ensuring that most examples have functional margin at least .