Discriminant Function
Binary Classification
Criteria:
Here is the separating surface
Loss Function
Classification
Regression
Least Squares Method
For linear function , where
is the augmented sample vector.
For samples , we define the design matrix
and
we have
we want to minimize
the solution is
Linear Discriminant Analysis
When working with high-dimensional datasets it is important to apply dimensionality reduction techniques to make data exploration and modeling more efficient. One such technique is Linear Discriminant Analysis (LDA) which helps in reducing the dimensionality of data while retaining the most significant features for classification tasks. It works by finding the linear combinations of features that best separate the classes in the dataset.
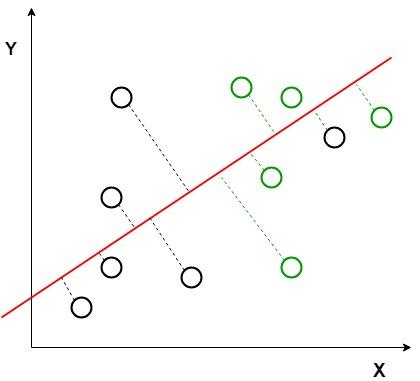 Image shows an example where the classes (black and green circles) are not linearly separable. LDA attempts to separate them using red dashed line. It uses both axes (X and Y) to generate a new axis in such a way that it maximizes the distance between the means of the two classes while minimizing the variation within each class. This transforms the dataset into a space where the classes are better separated.
Image shows an example where the classes (black and green circles) are not linearly separable. LDA attempts to separate them using red dashed line. It uses both axes (X and Y) to generate a new axis in such a way that it maximizes the distance between the means of the two classes while minimizing the variation within each class. This transforms the dataset into a space where the classes are better separated.
Logistic Regression
We could approach the classification problem ignoring the fact that is discrete-valued, and use our old linear regression algorithm to try to predict given . However, it is easy to construct examples where this method performs very poorly. Intuitively, it also doesn't make sense for to take values larger than or smaller than when we know that . To fix this, let's change the form for our hypotheses . We will choose
where
is called the logistic function or the sigmoid function.
Let us assume that
Note that this can be written more compactly as
Assuming that the training examples were generated independently, we can then write down the likelihood of the parameters as
As before, it will be easier to maximize the log likelihood:
Similar to our derivation in the case of linear regression, we can use gradient ascent. Written in vectorial notation, our updates will therefore be given by . (Note the positive rather than negative sign in the update formula, since we're maximizing, rather than minimizing, a function now.) Let's start by working with just one training example , and take derivatives to derive the stochastic gradient ascent rule:
This therefore gives us the stochastic gradient ascent rule
Perceptron
Consider modifying the logistic regression method to force it to output values that are either or or exactly. To do so, it seems natural to change the definition of to be the threshold function
If we then let as before but using this modified definition of , and if we use the update rule
then we have the perceptron learning algorithm.
Multi-Class Classification
We introduce groups of parameters , each of them being a vector in . Intuitively, we would like to use to represent the probabilities . However, there are two issues with such a direct approach. First, is not necessarily with . Second, the summation of 's is not necessarily . Instead, we will define the softmax function
The inputs to the softmax function, the vector here, are often called logits. The output of the softmax function is always a probability vector whose entries are non-negative and sum up to .
Let , we obtain the following probabilistic model
that is
The negative log-likelihood of a single example , is
Thus the loss function is given as
It's convenient to define the cross-entropy loss , which modularizes in the complex equation above
With this notation, we can simply rewrite the total loss into