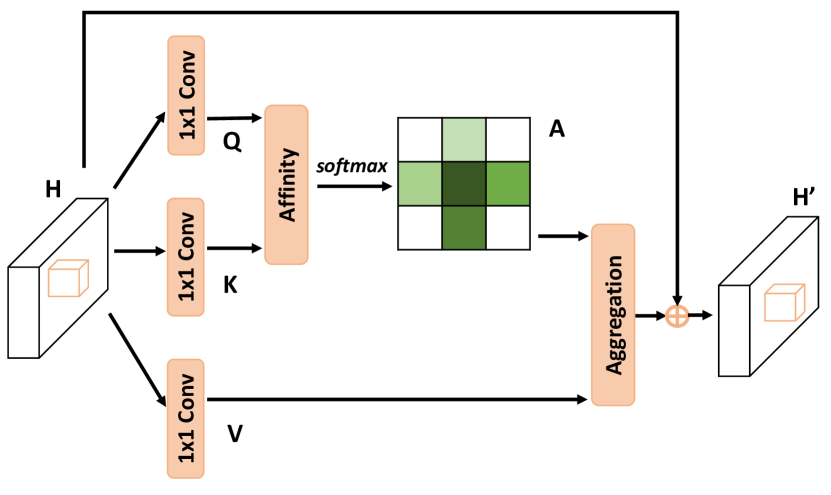
Idea
To improve the Non-local mechanism, for each pixel, we don't need to compute the attention scores of all the pixels in its region of interest. Instead, if in a module we just collect the contextual information in horizontal and vertical directions, then after feeding the result of the first module to a second one, the additional contextual information obtained form the criss-cross path finally enables the full image dependencies of all positions.
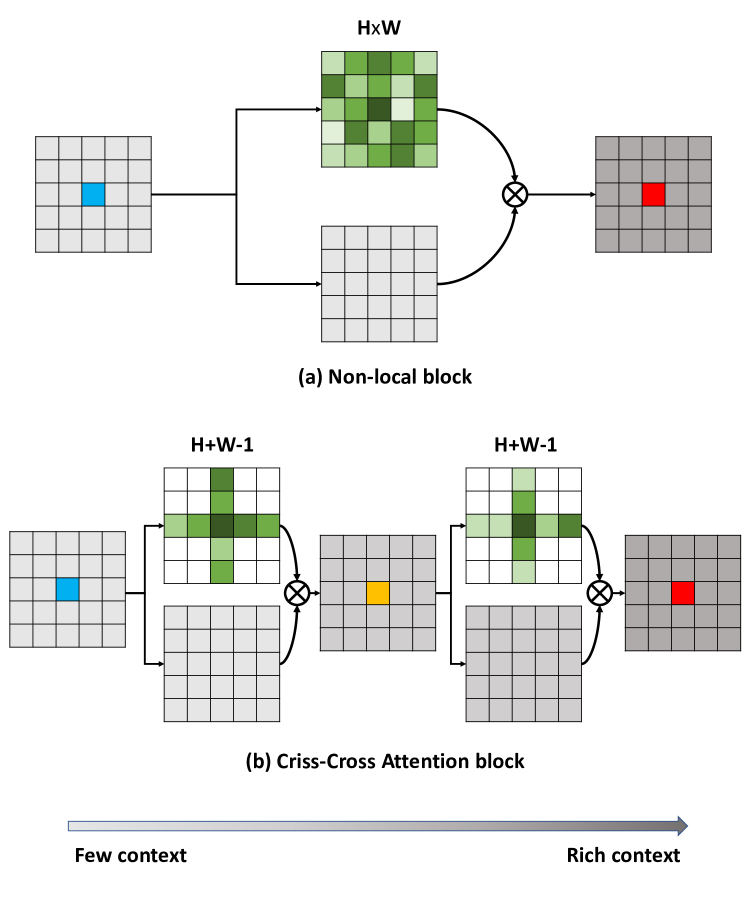
Architecture
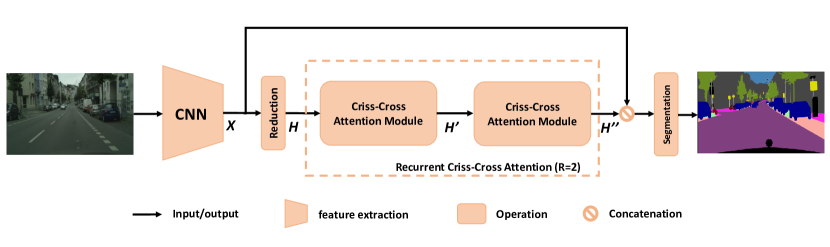
Criss-Cross Attention Module