Definition
Semantic segmentation is simply the task of assigning a class label to every single pixel of an input image.
Semantic vs Instance vs Panoptic
| Segmentation Type | Definition | Key Characteristics | Applications |
|---|---|---|---|
| Semantic Segmentation | Assigns a class label to each pixel in an image without distinguishing instances. | - Focuses on classifying pixels into categories (e.g., road, sky). - Treats multiple objects of the same class as one entity. | - Scene understanding (e.g., road and sky recognition) - Medical imaging for tissue classification. |
| Instance Segmentation | Identifies and segments individual object instances within an image. | - Differentiates between instances of the same class (e.g., each car or person). - Assigns unique masks or bounding boxes to each object. | - Counting objects (e.g., cars on a road) - Robotics and autonomous vehicles for object detection. |
| Panoptic Segmentation | Combines semantic and instance segmentation to provide a complete scene understanding. | - Each pixel is labeled with both a semantic class and an instance ID. - Resolves conflicts between overlapping segments. | - Comprehensive scene analysis in autonomous vehicles - Advanced applications in robotics and AI. |
The Naive Approach - Sliding Windows
Imagine a sliding window of some dimensions ( or ) and for each window, we can try to classify the center pixel. By this way, we convert the segmentation task to a classification task
Limitations:
- Inefficient: does not use the features shared by different windows
- Narrow context windows: cannot access global feature
CNN-based Networks
Idea
Apply convolutional layers to downsampling, which
- Enables a progressive increase of receptive field
- Save memory and computational cost And the final captured high-level features are feed into a upsampling module, first invented in FCN, to output the segmentation results
Upsampling Methods
- Bed of nails: for each upsampled patch, the top-left pixel is the original pixel before unpooling, and all the rests are set to zeros
- Nearest neighbor: just copy the pixel to fill all the positions of the patch upsampled from this pixel
- Max Unpooling:
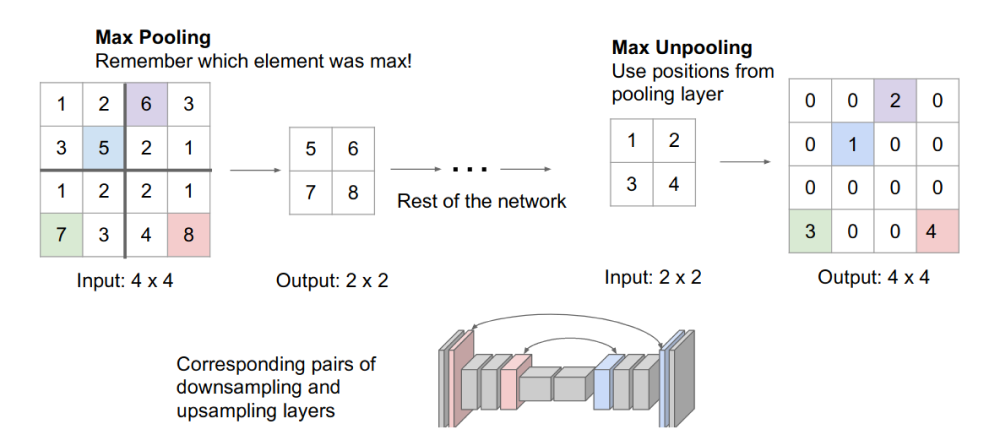
- Transposed Convolution: with learnable parameters
Encoder-Decoder Architecture
Proposed by U-Net, applying skip connections to restore the information lost during the downsampling process in encoder
Dilated Convolution
Proposed by DeepLab v1, expanding the receptive field while keeping the size of parameters. With proper padding, dilated convolution can also save the resolution of the input image so that less spatial information would be lost
Tackling with Different Scales
- PSPN: Pyramid Pooling
- RefineNet: Fusing features from different stages using convolutions
- ICNet: Improve PSPN for real-time and high-resolution tasks, with lighter-weight CNNs for low-level stages (having higher resolution)
Separate Spatial and Context
BiSeNet, BiSeNet v2: shallow layers for spatial features; fast, lightweight downsampling for context features
Non-local Paradigm
Non-local Neural Networks introduces attention mechanism for segmentation, enlarging the receptive field to the whole image
Based on this,
- PSANet improves the attention mechanism with bidirectional paths: collect and distribute
- DAN computes attention scores both position-wise and channel-wise
- CCNet proposes criss-cross attention to save computational cost. At each module just collect the information in horizontal and vertical directions, then every two modules each pixel could capture the information from the whole feature map
- ANN embeds Pyramid Module to non-local blocks, and beside for self-attention scores, this model also computes attention scores between low-level and high-lebel feature maps
- GCNet notices that in images the attention map for each query is almost the same. So they simplify the non-local block to apply query-independent computation
Giving some hint first
OCRNet aggregates the pixel with its region information (the category this pixel belongs to predicted by the backbone network, regularized by the ground-truth segmentation with a auxiliary loss during training) to obtain Object Region Representations.
EncNet first looks at the global information to get the possible categories, then computes how similar each pixel is with these categories. The result is used to apply weights for each channel.
Lesson from Computer Graphics
PointRend views image segmentation as rendering problem and to adapt classical idea from computer graphics to efficiently "render" high-quality label maps, that is, for each "rendering" iteration focus on the most ambiguous points to recover detail on the finer gird.
Vision Transformer-based Models
Advantages
- Vision transformer foregoes explicit downsampling operations after an initial image embedding has been computed and maintains a representation with constant dimensionality throughout all processing stages
- The transformer has a global receptive field at every stage after the initial embedding.
Models
DPT assembles tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder
Segmenter, on the other hand, applies a mask-transformer as the decoder and upsample the masked classes to generate the segmentation map. This make the decoder focuses on specific foreground areas, and could help in extracting more relevant and localized features for segmentation
SegFormer applies Hierarchical Transformer Encoder to produce multiscale features, using overlapped patches to improve local continuity and convolution to extract positional information so that positional encoding is not necessary. A Lightweight MLP Decoder is also proposed to aggregates information from various layers while save computational cost