Idea
- Instead learning from a fixed set of predetermined object categories, why not directly learn from texts about images. (This is an multi-modal model since it maps both texts and images into the same feature space)
- Use the pre-trained model to perform zero-shot image classification. Aim to classify images it has never seen before by using natural language descriptions without requiring specific training on those categories.
Method
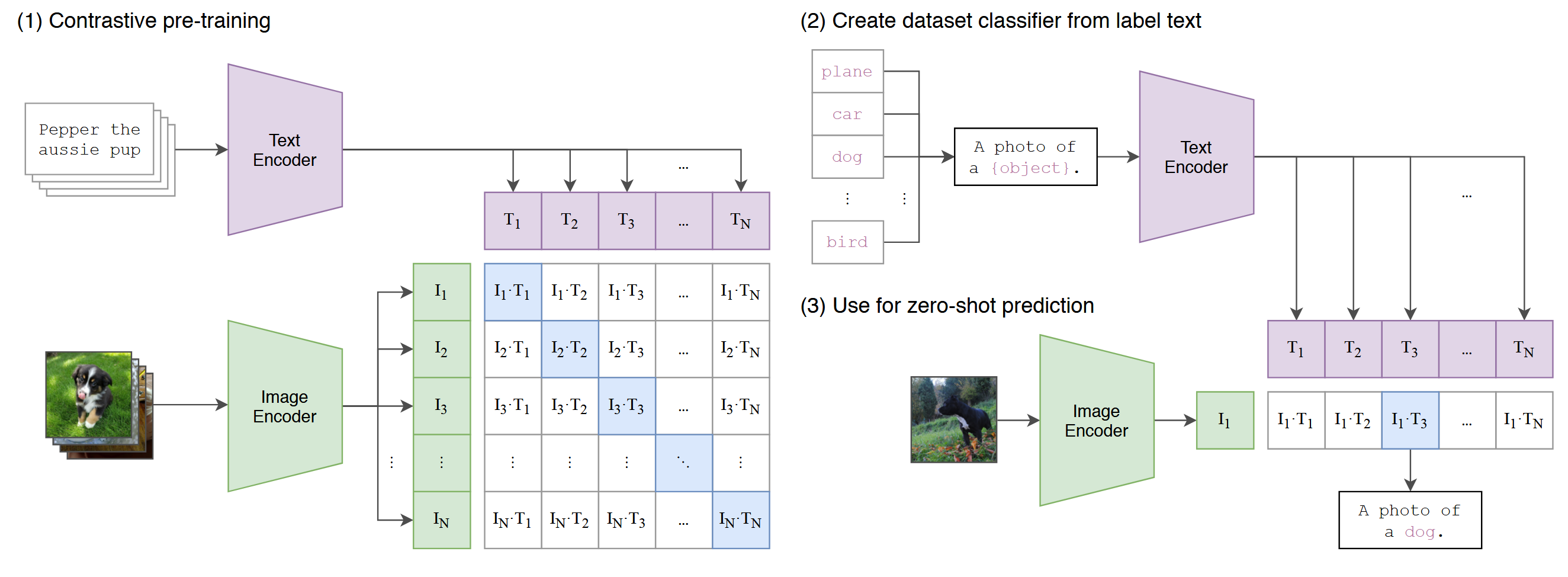
Contrastive pre-training
Given a set of images and the corresponding texts describing them, the model should learn to pair each image with the correct descriptive text by encoding them into the same feature space and compute the similarity between them (use dot-product). This is known as contrastive learning
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2Create dataset classifier from label text
Input your interested label object to generate a text template A photo of a {object}, then the templates are fed into a text encoder
Use for zero-short prediction
Given a image, the prediction result is the text template that has the biggest similarity score with the image in the feature space.