Idea
Goal
Build a foundation model for image segmentation: develop a prompt-able model and pre-train it on a board dataset using a task that enables powerful generalization
Three key components
- What task will enable zero-shot generalization
- What is the corresponding model architecture
- What data can power this task and model
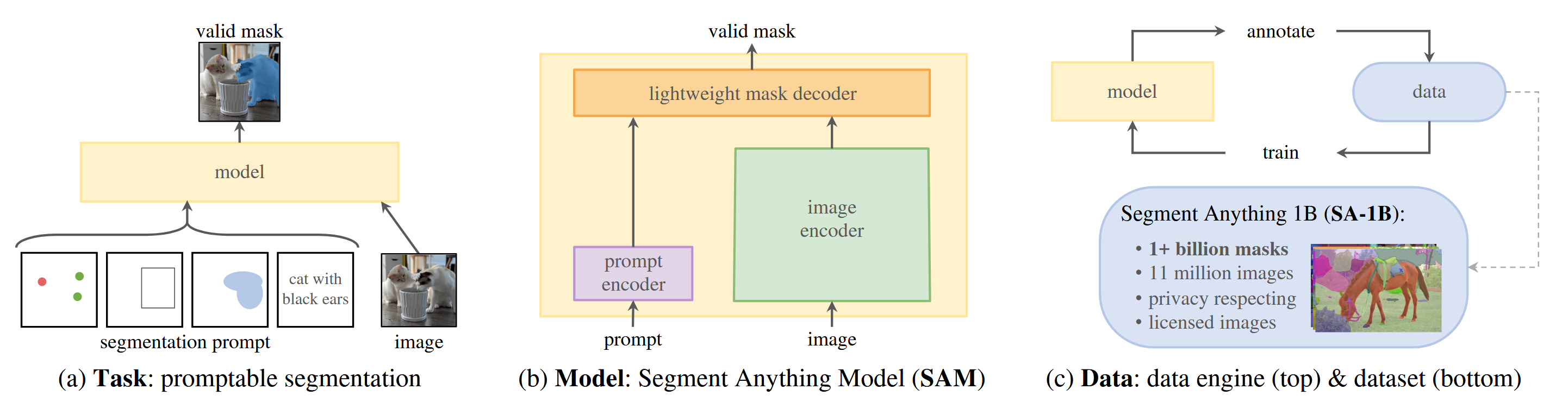
Task
Task Types
- A set of foreground / background points
- A rough box or mask
- Free-from text The prompt-able segmentation task is to return a valid segmentation mask given any prompt. The requirement of a valid mask simply means that even when a prompt is ambiguous and could refer to multiple objects, the output should be a reasonable mask for at least one of those objects.
Pre-training
The prompt-able segmentation task suggests a natural pre-training algorithm that simulates a sequence of prompts (e.g. points, boxes or masks) for each training sample and compares the model's mask predictions against the ground truth.
Zero-shot Transfer
Intuitively, the pre-training task endows the model with the ability to respond appropriately to any prompt at inference time, and thus downstream tasks can be solved by engineering appropriate prompts
For example, if one has a bounding box detector for cats, cat instance segmentation can be solved by providing the detector's box output as a prompt to this model.
Model
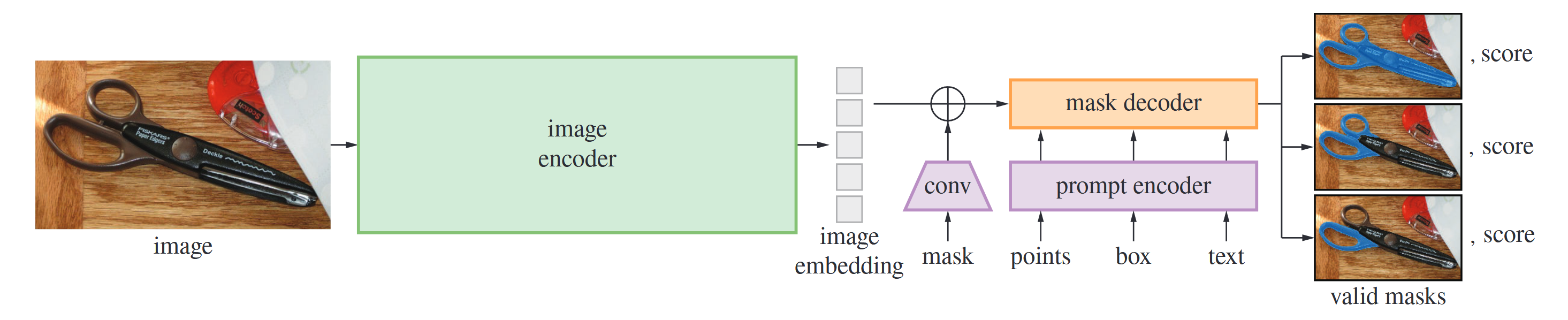
Image Encoder
Apply an MAE pre-trained Vision Transformer (ViT) minimally adapted to process high resolution inputs
Prompt Encoder
Represent points and boxes by positional encodings summed with learned embedding for each prompt type and free-form text with an off-the-shelf encoder from CLIP
Mask Decoder
Employs modification of a Transformer decoder block followed by a dynamic mask prediction head. The modified decoder block uses prompt self-attention and cross-attention in two directions (prompt-to-image embedding and vice-versa) to update all embeddings.
Data
As segmentation masks are not abundant on the internet, the authors built a data engine to enable the collection of their 1.1B mask dataset, SA-1B. The data engine has three stages
- A model-assisted manual annotation stage
- A semi-automatic stage with a mix of automatically predicted masks and model-assisted annotation
- A fully automatic stage in which the model generates masks without annotator input
Code Implementation
Prompt Encoder Module
Input
The forward method takes in three kinds of prompts:
points: tuple(Tensor, Tensor)where the two tensors represents point coordinates and labels to embed. And the label can be0if the point belongs to the object you want to segment1if you want to exclude the point from the object
boxes: Tensormasks: Tensor.
Embed Points
- Apply
points += 0.5to shift the points to center of pixel - If the input
boxesisNone, for each minibatch, pad point(0, 0)and label-1at the end of the batch - Normalize the
pointsto[0, 1]relative to the whole image size and then add positional encoding, return shape - Add additional point embedding according to the labels, and finally returns the
points
Embed Boxes
- Apply
boxes += 0.5to shift the points to center of pixel - Reshape to , and the do the normalization and add positional encoding, return shape
- Add corner embeddings to distinguish the left-up corner point and the right-down corner point
Embed Masks
- Apply convolutional layers to downscale the masks to the target shape
- If no input masks are given, use
no_masks_embeddinginstead
Output
Two kinds of embeddings as the output:
sparse_embeddings: Tensorfor the points and boxes with shape , where if , otherwisedense_embeddings: Tensorfor the masks with shape , where is the spatial size of the image embedding.