Idea
Improve the semantic segmentation results by effectively utilizing global context, which captures the semantic context of scenes and selectively enhances class-dependent feature maps.
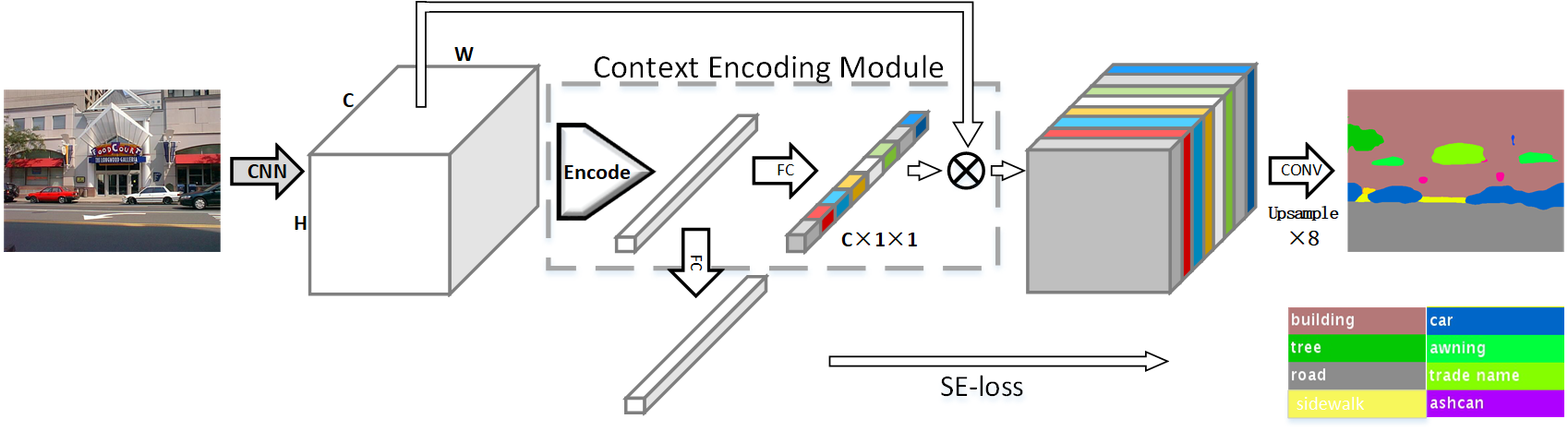
Context Encoding Module
Encoding Layer
Input
Considering the input feature map with the shape of as a set of -dimensional input features , where
Codebook
The Encoding Layer learns a codebook containing codewords (or visual centers)
Each represents a distinct visual center in the feature space that captures a specific semantic meaning or category in the input data
Smoothing Factor
Alongside the codebook, the layer also learns a set of smoothing factors
Each corresponds to a smoothing factor for the visual center . These factors are used to control the influence of each visual center on the feature representation
Output
The layer outputs the residual encoder by aggregating the residuals with soft-assignment weights , where
and the residuals are given by . The final output is , where denotes Batch Normalization with ReLU activation. ( is a -dimensional vector)
Feature Map Attention
Use a fully connected layer to predict feature map scaling factors , where denotes the layer weights and is the sigmoid function. Then the module output is given by .