Idea
 Visualization shows that the global contexts modeled by Non-local Neural Networks are almost the same for different query positions within an image (The figure above shows the attention maps for different query positions (red points) in a non-local block on COCO object detection)
Visualization shows that the global contexts modeled by Non-local Neural Networks are almost the same for different query positions within an image (The figure above shows the attention maps for different query positions (red points) in a non-local block on COCO object detection)
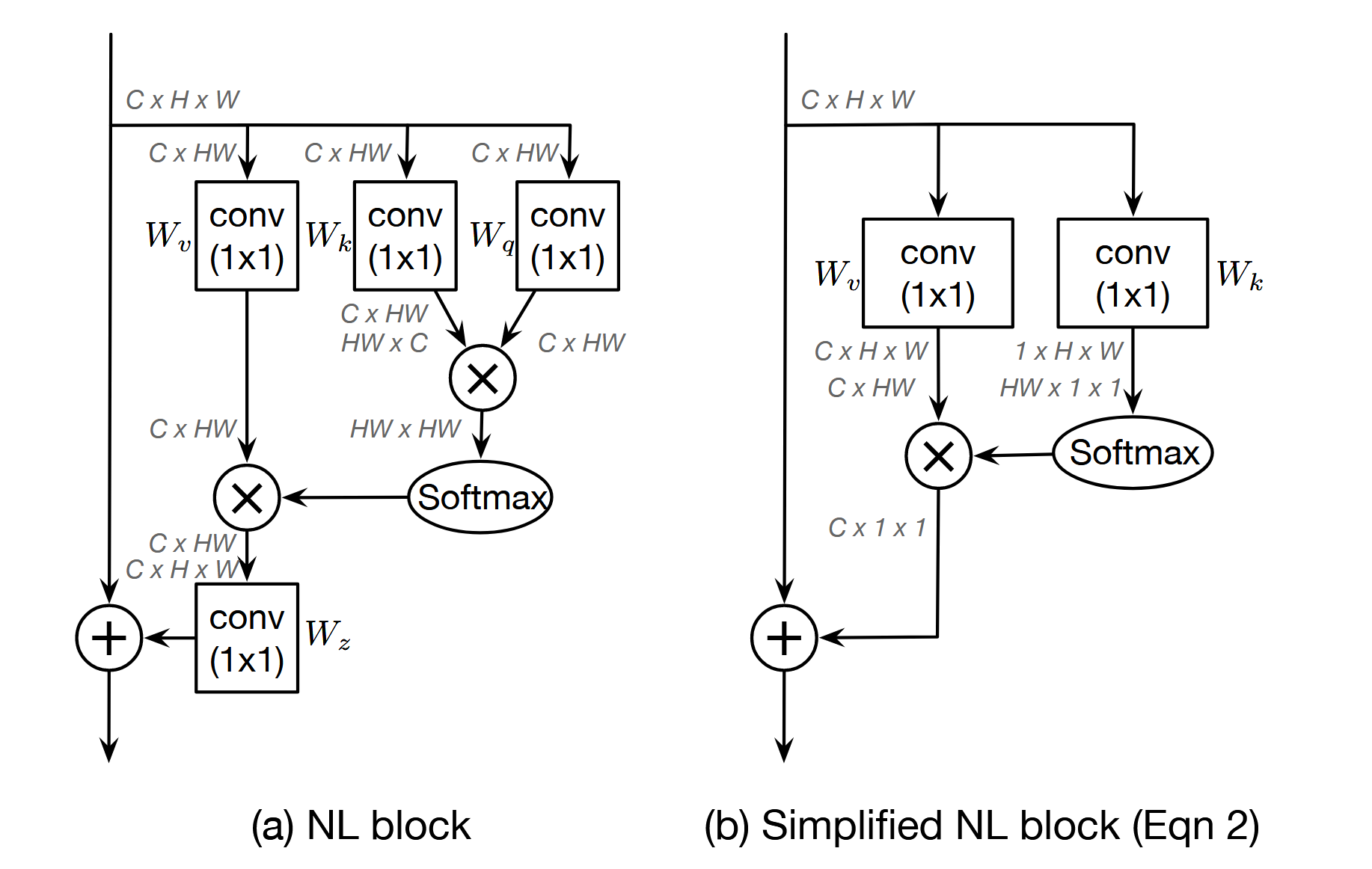
Therefore, we could simplify the non-local block by explicitly using a query-independent attention map for all query positions. Then we add the same aggregated features using the attention map to the features of all query positions to form the output
Simplify the Non-local Block