Idea
Based on MaskFormer,
- Apply masked attention in the decoder
- Use multi-scale high-resolution features
Architecture
Difference from MaskFormer:
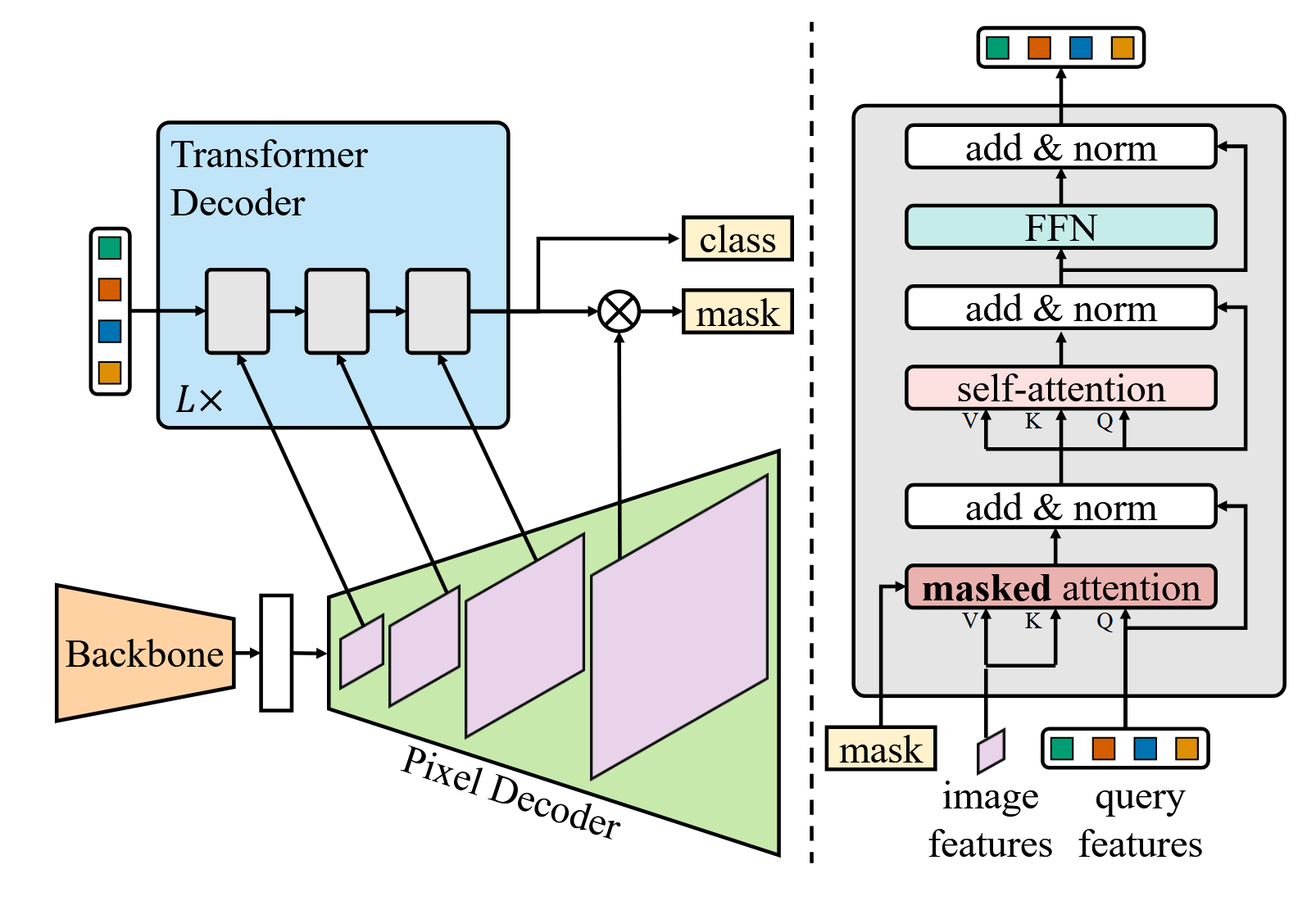
Masked Attention
Constrain cross-attention within predicted mask regions, other than the whole image
From ( is the layer index, and is the query features at -th layer)
to
where
here is the binarized output (with threshold at ) of the resized mask prediction of the previous -th Transformer decoder layer
High-resolution features
Instead of always using the high-resolution feature map, utilize a feature pyramid which consists of both low- and high-resolution features and feed one resolution of the multi-scale feature to one Transformer decoder layer at a time.
Specifically, use the feature map produced by the pixel decoder with resolution , and of the original image.