Idea
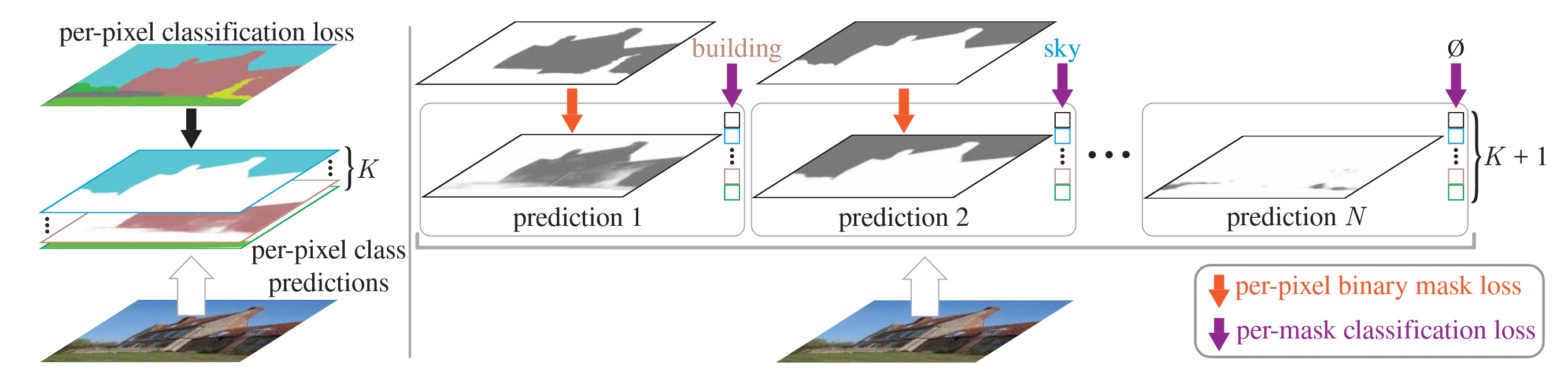 Instead for pre-pixel classification, we could first predict a set of binary masks and then assign a single class to each mask.
Instead for pre-pixel classification, we could first predict a set of binary masks and then assign a single class to each mask.
Each prediction is supervised with a per-pixel binary mask loss and a classification loss
Architecture
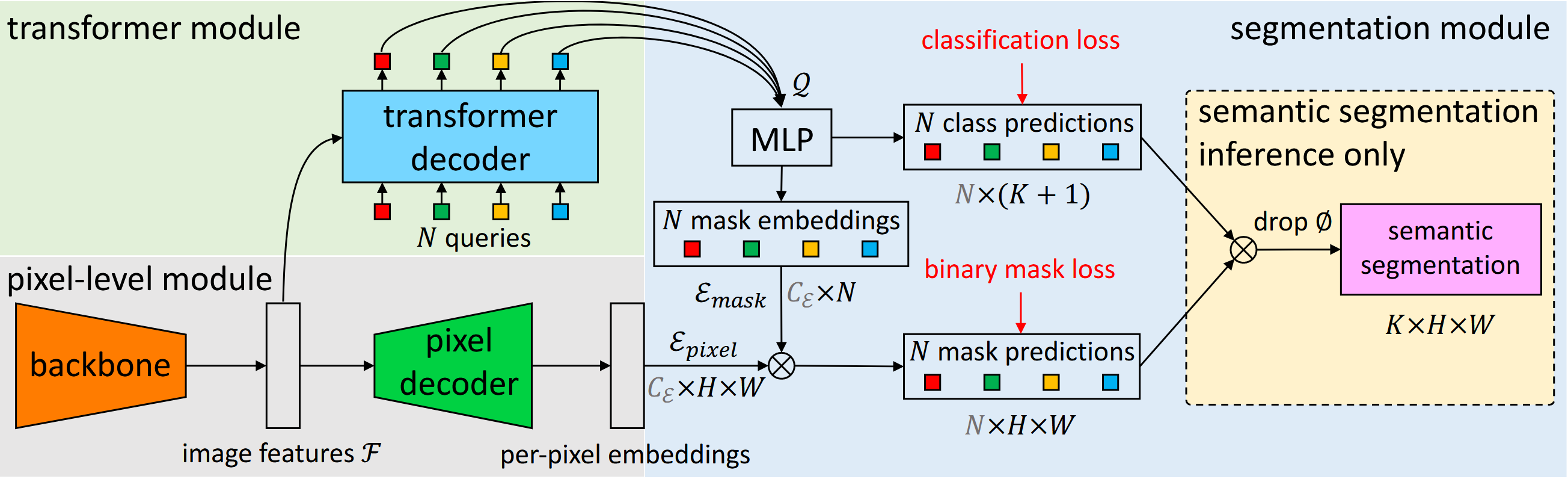
- Using a backbone to extract images features
- Upsample the features to obtain per-pixel embeddings
- A transformer decoder attends to image features and produces per-segment embeddings , then embeddings then independently generate
- class predictions (shape ), where is introduced to represent "no-object" class
- corresponding mask embeddings
- Predict possibly overlapping binary mask predictions via a dot product between pixel embeddings and mask embeddings followed by a sigmoid activation.
- Finally we can get the prediction by combining binary masks with their class predictions using a simple matrix multiplication.