Idea
Propose a universal model for semantic, instance and panoptic segmentation (See differences), which just requires once-and-for-all training.
- Introduce a task token to condition the model on the task at hand
- Use a query-text contrastive loss
Architecture
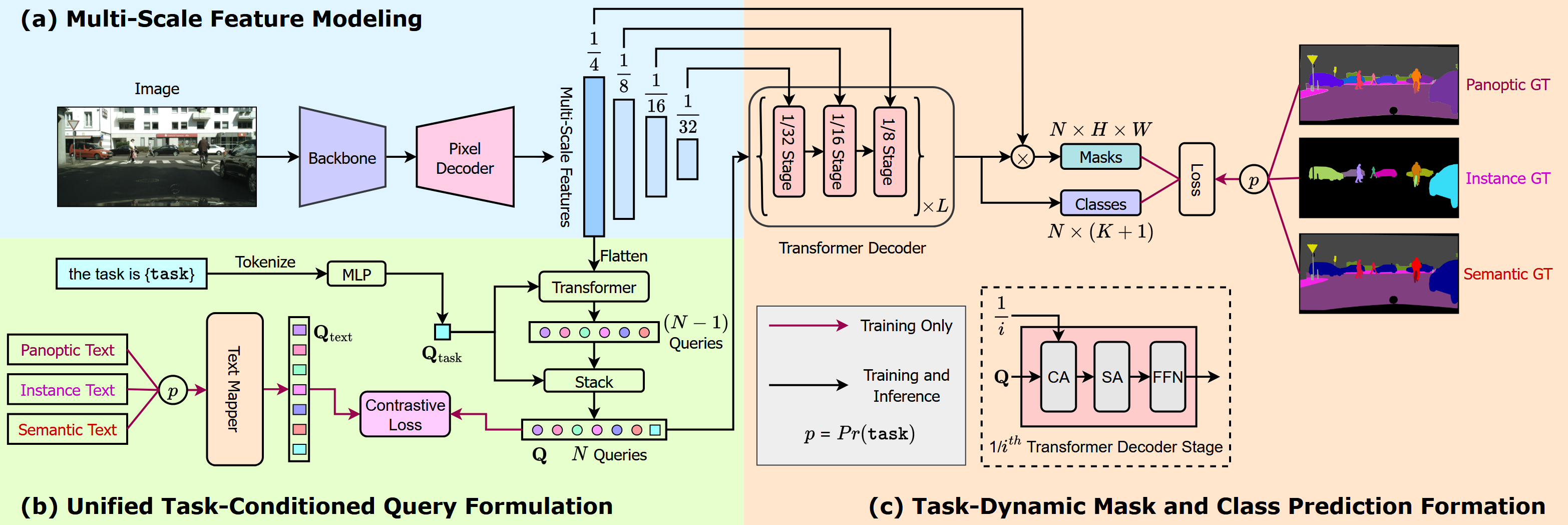
Multi-Scale Feature Modeling
Extract multi-scale features for an input image using a backbone, followed by a pixel decoder (translating the high-level features into pixel-level predictions)
Unified Task-Conditional Query Formulation
Task Input Token
Uniformly sample {task} from {panopitc, instance, semantic} to form the task input token
At the same time, uniformly sample the corresponding ground truth to generate text queries
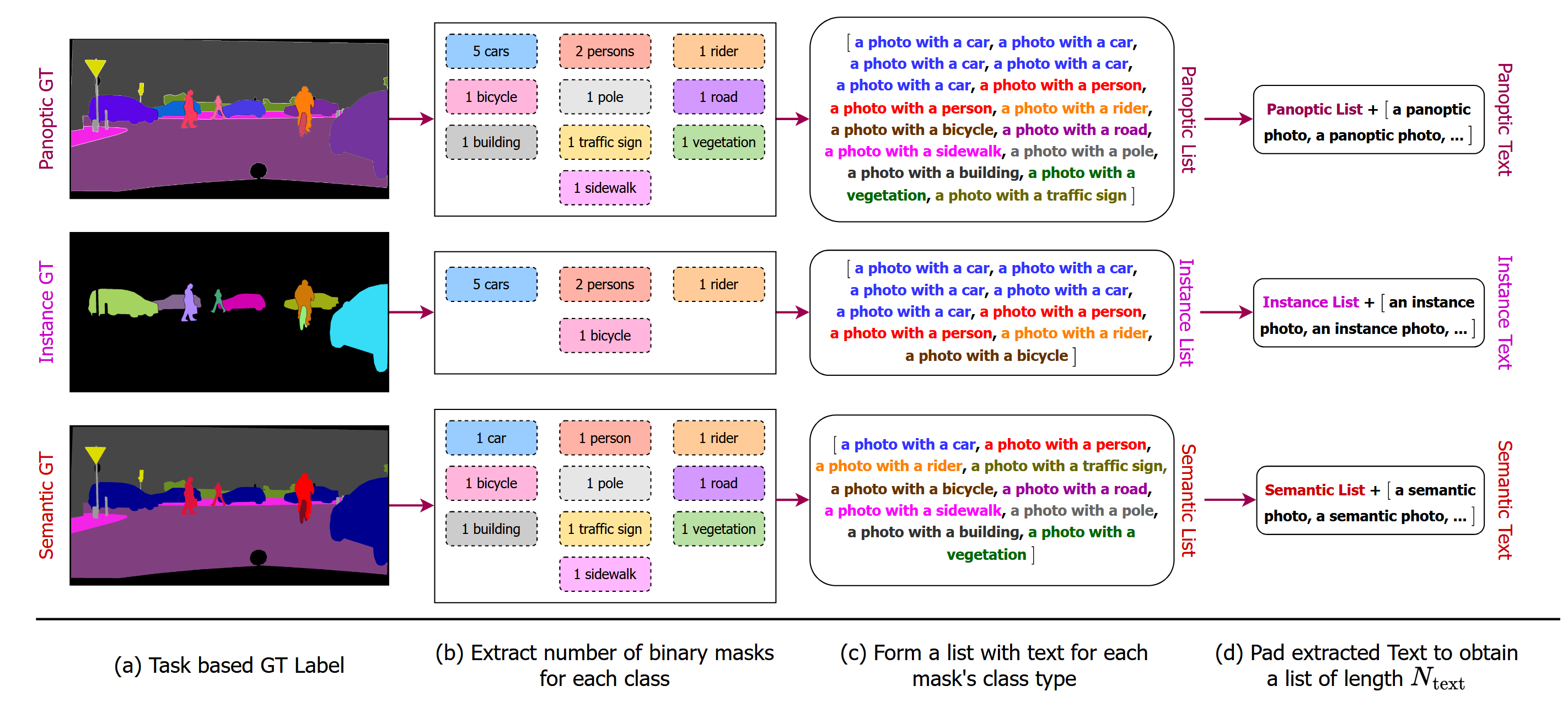
Text Query ()
As shown below, first iterate over the set of masks to create a list of text () with a template a photo with a {CLS}. Then pad with a/an {task} entries to obtain a padded list () of constant length , with padded entries representation no-object masks.
 To obtain the text queries , we first tokenize the text entries and pass the tokenized representation through a text-encoder, which is a -layer transformer. The encoded text embeddings represent the number of binary masks and their corresponding classes in the input image. We further concatenate a set of learnable text context embeddings to the encoded text embeddings to obtain the final text quires
To obtain the text queries , we first tokenize the text entries and pass the tokenized representation through a text-encoder, which is a -layer transformer. The encoded text embeddings represent the number of binary masks and their corresponding classes in the input image. We further concatenate a set of learnable text context embeddings to the encoded text embeddings to obtain the final text quires
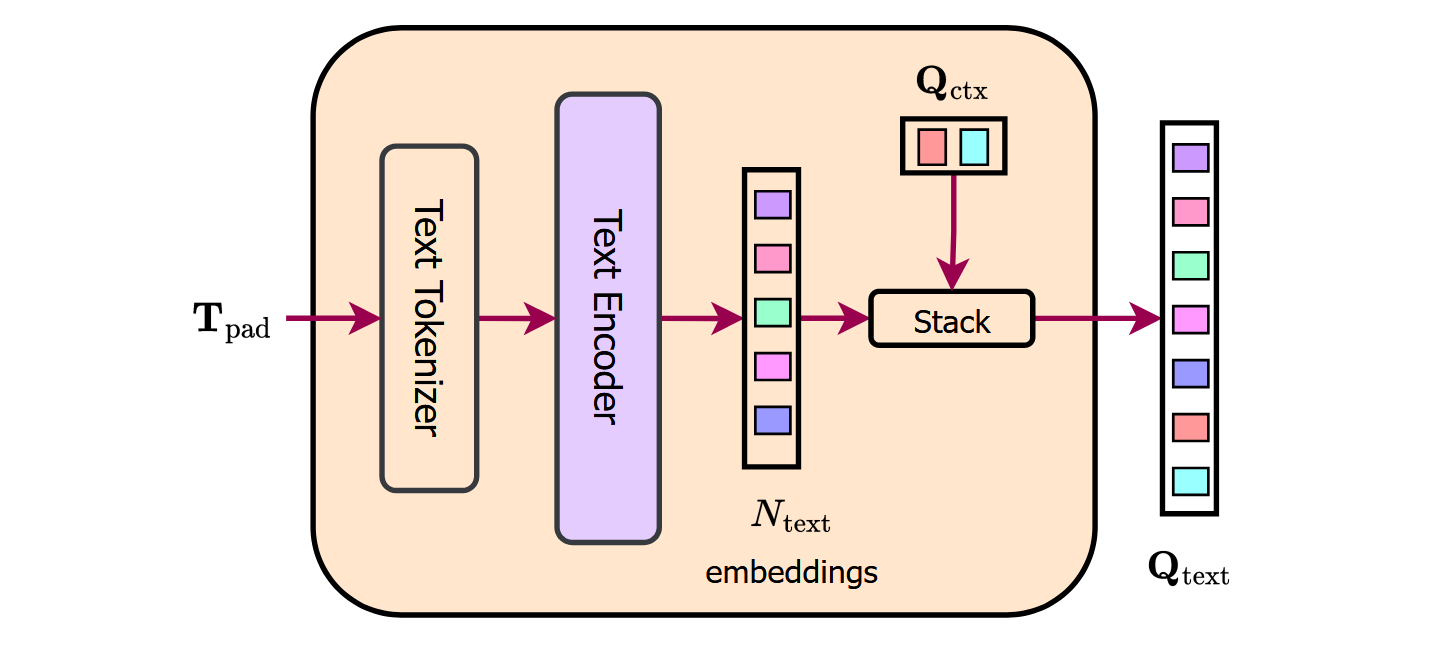 The goal of is to provide a unified textual context that captures the relevant information necessary for various tasks, such as image segmentation.
The goal of is to provide a unified textual context that captures the relevant information necessary for various tasks, such as image segmentation.
Object Query ()
First initialize the object queries () as times repetitions of the task-token . Then update with guidance from the flattened -scale features inside a -layer transformer. The updated from the transformer (rich with image-contextual information) is concatenated with to obtain a task-conditioned representation of queries,
Query-Task Contrastive Loss
Considering that we have a batch of object-text query pairs , where and are the corresponding object and text queried, respectively, of the -th pair, we measure the similarity between the queries by calculating a dot product.
Here is a learnable temperature parameter to scale the contrastive logits.