Idea
Another real-time object detection model faster than YOLO. The core of SSD is predicting category scores and box offsets for a fixed set of default bounding boxes using small convolutional filters applied to feature maps
Method
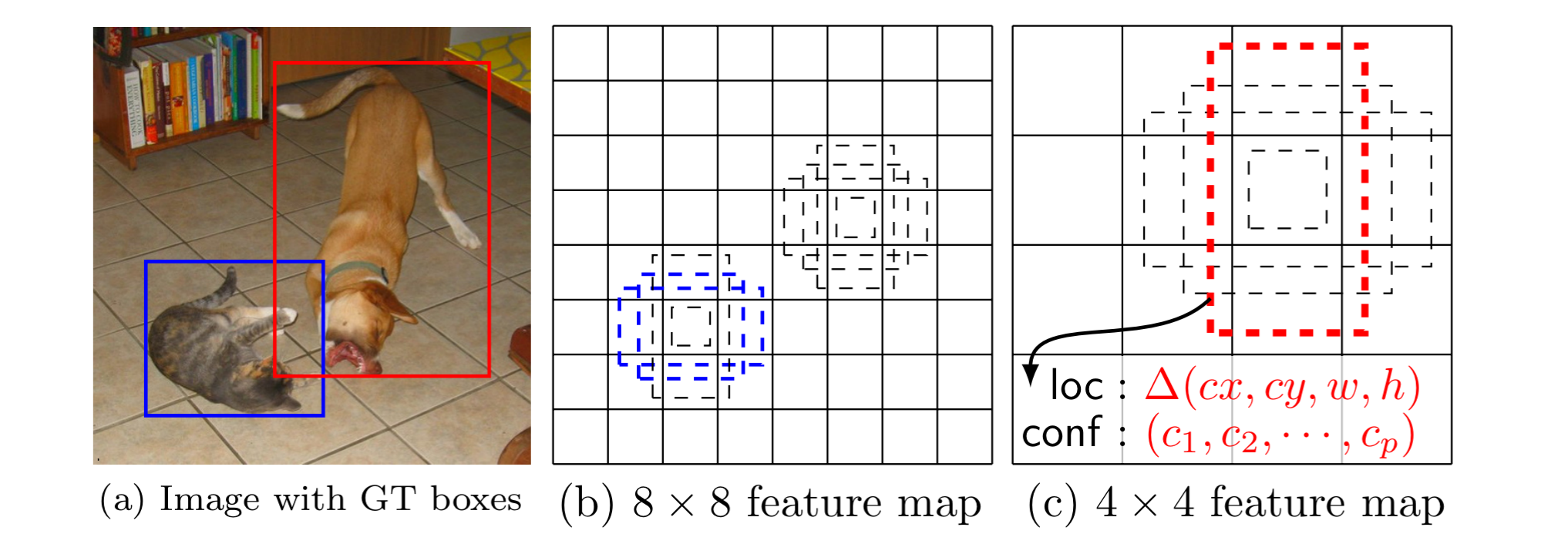
- Evaluate a small set (e.g. in the figure above) of default boxes (just like the anchors in Faster R-CNN) of different aspect ratios at each location in several feature maps with different scales (e.g and in (b) and (c) ).
- For each default box, predict both the shape offsets and the confidences for all object categories ()
Architecture
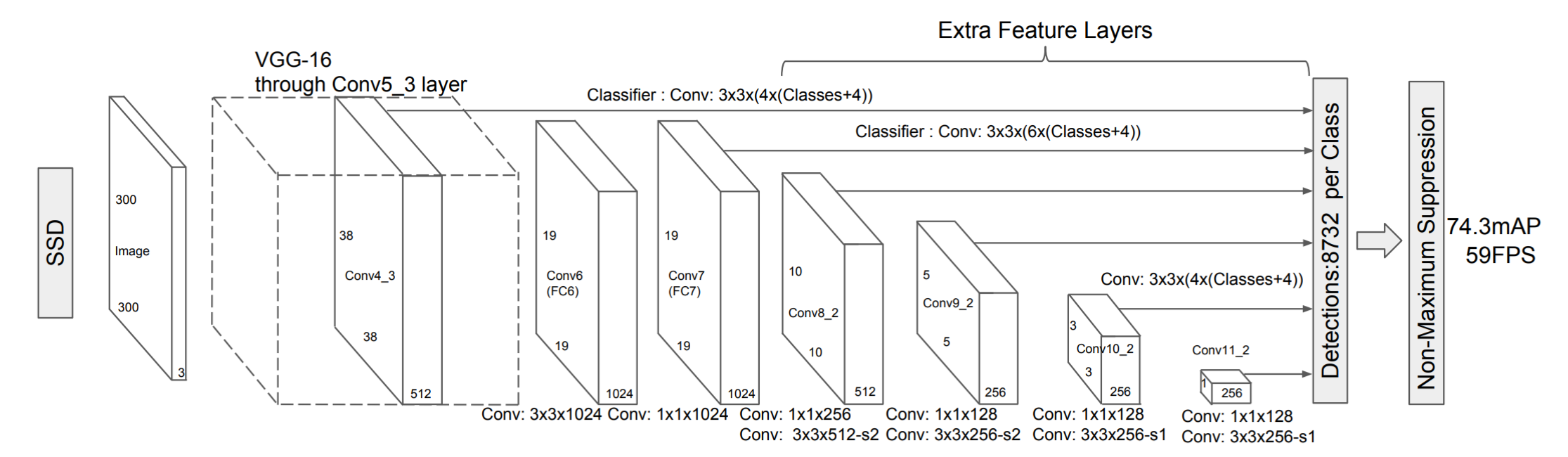
- The model is bases on a standard classification network
- Convolutional feature layers are added to the end of the backbone network. These layers decrease in size progressively and allow predictions of detections at multiple scales.
- For each feature layer of size with channels, the basic element for predicting parameters of a potential detection is a small kernel that produces either a score for a category, or a shape offset relative to the default boxes coordinates. At each of the locations where the kernel is applied, it produces an output value.