Idea
The "SW" in "Swin" stands for Shifted Windows.
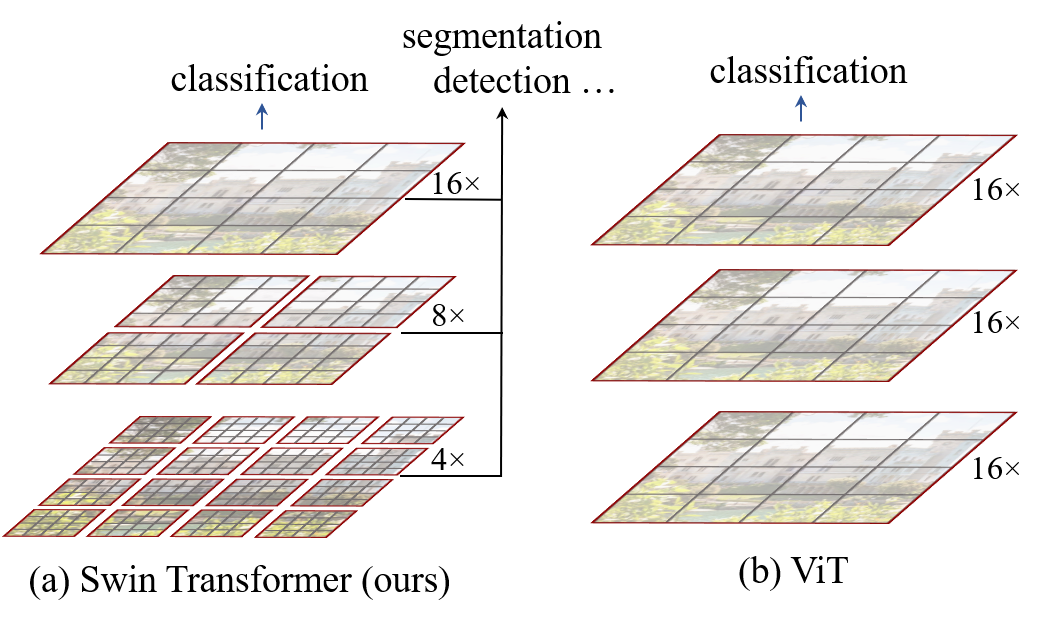
Issues with traditional vision transformer
- The scale of visual entities may vary: in a image there might be targets with different sizes but represent the same semantic value such as a person.
- Difficulties with high-resolution pictures: the traditional patches may result in exploded sequence size when tacking with high-resolution pictures.
Shifted windows
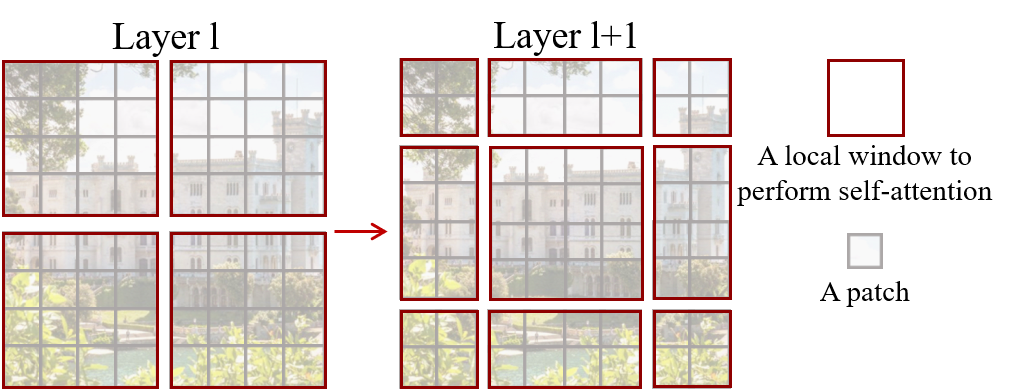
- Window: Only compute self-attention in the selected window. For example, in the last layer of figure (a) below, the whole picture is sliced into windows, and each window have pixels patches. The model views a window as a sequence and calculate the self-attention scores inside the window. After this, every non-overlapping patches in the neighborhood are concatenated, as well as the windows. Therefore we can calculate self-attention in these windows once again.
- Shift: Shift the windows across layers to realize cross-windows connection. In the following figure, the windows are shifted by patches rightward and patches downward from layer to layer
Model
![]()
- Convert Image to patches
- Stage
- Create embedding vectors for each patch from its original pixels
- Swim Transformer Block (the shape of outputs is the same as inputs) ()
- Apply layer normalization
- Calculate Windowed (Shifted in the second block) Multi-head Self Attention
- Add the attention scores to the input
- Apply layer normalization
- MLP feed-forward layer
- In the first block, pass the output as the input of the second block
- Stage
- Patch Merging
- Let the input size be , if apply dilation , for example, we label to a patches input, and then merge the patches with the same label to obtain -patch tensors (in general, tensors)
- Concatenate these tensors into a tensor
- Project to a tensor as the output via convolutions
- Swim Transformer Block ()
- Patch Merging
- Stage : cut the to its half size and double the channel number
- ...