Idea
Another application of Vision Transformer (ViT) in semantic segmentation, with
- Hierarchical Transformer Encoder to produce multiscale features. Mix-FFN proves convolution is enough to provide positional information so that the positional encoding can be avoided.
- Lightweight MLP Decoder combines both local and global attention mechanisms, allowing the model to generate powerful representations without the complexity typically associated with traditional decoders
Architecture
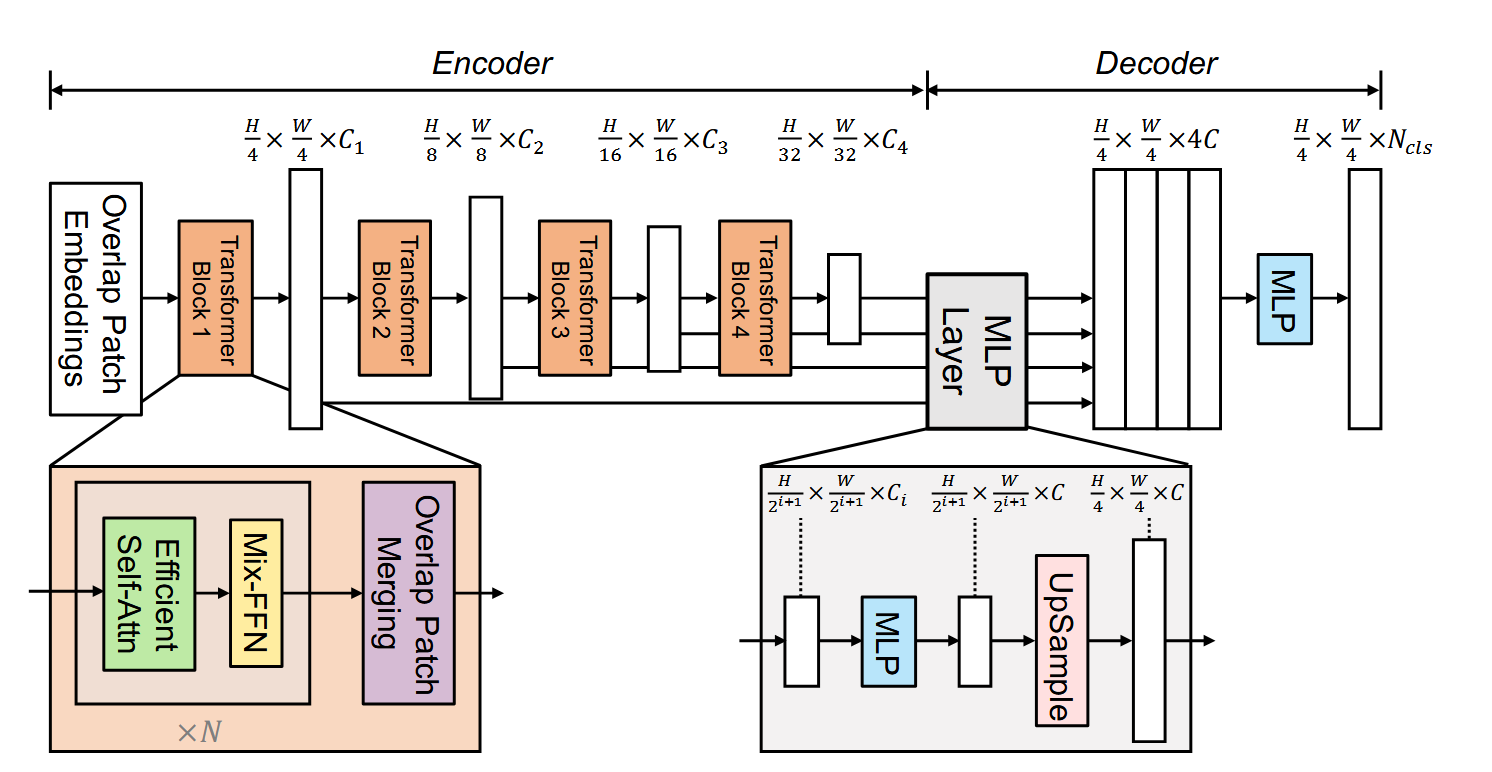
Overlap Patch Merging
Allows for the unification of features from overlapping patches, which enhances the model's ability to preserve local details. Compared to non-overlap patch merging (e.g. in Swin Transformer), this approach improves local continuity and supports flexible input sizes.