Motivation
Consider a classification problem in which we want to learn to distinguish between elephants () and dogs , based on some features of an animal. Given a training set, an algorithm like logistic regression or the perceptron algorithm (basically) tries to find a straight line—that is, a decision boundary—that separates the elephants and dogs. Then, to classify a new animal as either an elephant or a dog, it checks on which side of the decision boundary it falls, and makes its prediction accordingly.
Here’s a different approach. First, looking at elephants, we can build a model of what elephants look like. Then, looking at dogs, we can build a separate model of what dogs look like. Finally, to classify a new animal, we can match the new animal against the elephant model, and match it against the dog model, to see whether the new animal looks more like the elephants or more like the dogs we had seen in the training set.
Algorithms that try to learn directly (such as logistic regression), or algorithms that try to learn mapping directly from the space of inputs to the labels (such as the perceptron algorithm) are called discriminative learning algorithms. Here, we’ll talk about algorithms that instead try to model . These algorithms are called generative learning algorithms. For instance, if indicates whether an example is a dog (0) or an elephant (1), then models the distribution of dogs' features, and models the distribution of elephant's features.
After modeling (the class priors) and , our algorithm can then use Bayes' Theorem to derive the posterior distribution on given :
Here the denominator is given by . Actually, if were calculating in order to make a prediction, then we don’t actually need to calculate the denominator, since
Gaussian Discriminant Analysis (GDA)
Multivariate normal distribution
The multivariate Gaussian distribution is parameterized by a mean vector and a covariance matrix , where is symmetric and positive semi-definite. Also written , its density is given by:
The GDA model
When we have a classification problem in which the input features are continuous-valued random variables, we can then use the Gaussian Discriminant Analysis (GDA) model, which models using a multivariate normal distribution. The model is:
where "Bernoulli" denotes the Bernoulli Distribution. Here, the parameters of our model are and . (Note that while there’re two different mean vectors and , this model is usually applied using only one covariance matrix .) The log-likelihood of the data is given by
By maximizing with respect to the parameters, we find the maximum likelihood estimate of the parameters to be:
Pictorially, what the algorithm is doing can be seen in as follows:
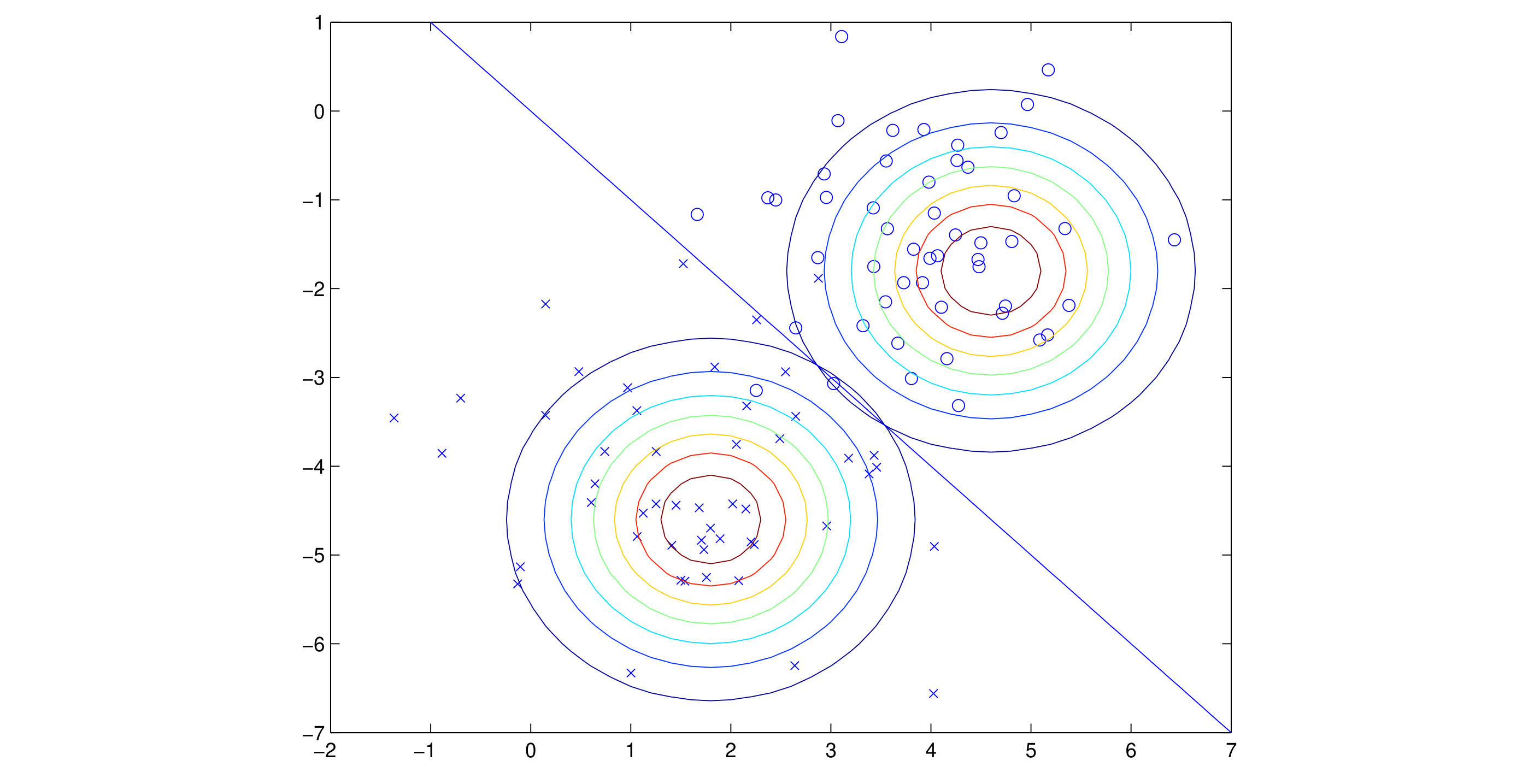 Shown in the figure are the training set, as well as the contours of the two Gaussian distributions that have been fit to the data in each of the two classes. Note that the two Gaussians have contours that are the same shape and orientation, since they share a covariance matrix , but they have different means and .
Shown in the figure are the training set, as well as the contours of the two Gaussian distributions that have been fit to the data in each of the two classes. Note that the two Gaussians have contours that are the same shape and orientation, since they share a covariance matrix , but they have different means and .
Discussion
- Form of : If is a multivariate Gaussian (with shared ), then necessarily follows a logistic function. Specifically, , which is the form logistic regression uses.
- Modeling Assumptions: GDA makes stronger assumptions about the data (specifically, that is Gaussian) than logistic regression. Logistic regression only assumes that takes the form of a logistic function, which can arise from various distributions of (e.g., Gaussian, Poisson).
- Data Efficiency and Accuracy: When GDA's modeling assumptions are correct (or approximately correct), GDA is more data-efficient (requires less training data) and can find better fits, especially with small training datasets. In the limit of very large training sets, GDA is asymptotically efficient.
- Non-Gaussian Data: If the data is non-Gaussian, logistic regression will often perform better than GDA in the limit of large datasets. If we were to use GDA on such data—and fit Gaussian distributions to such non-Gaussian data—then the results will be less predictable, and GDA may (or may not) do well.