Derive the ELBO
In variational inference we want to approximate the true posterior distribution from a known distribution family .
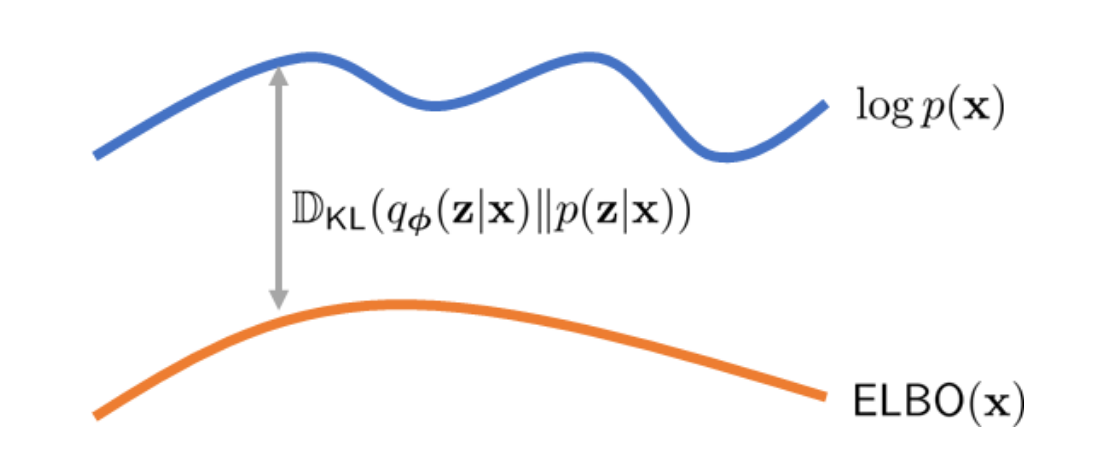
We often choose KL divergence as the loss function to measure the difference between two probability distributions. Therefore, we need to minimize
where we define
Then we have
Since the left hand side is constant (not depending on ), too minimize KL divergence is equivalent to maximize
Why Evidence Lower Bound
The name of ELBO comes from