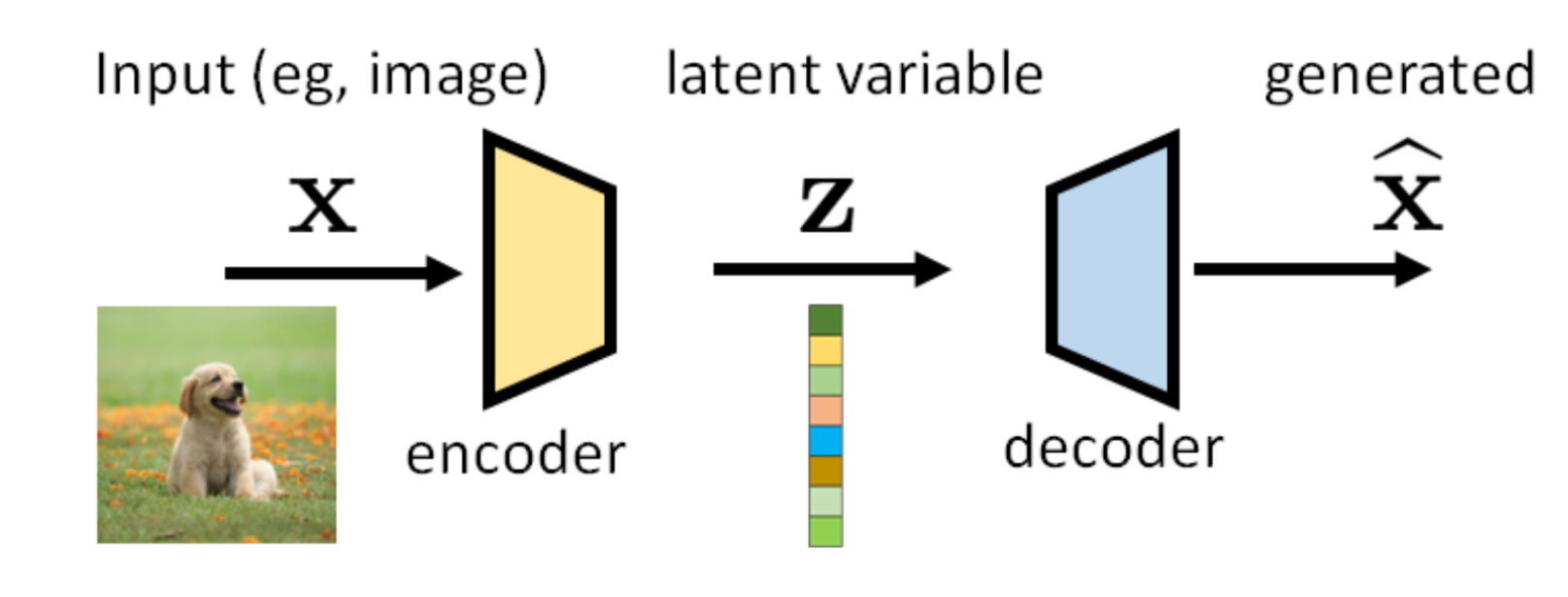
Model
A variational auto-encoder (VAE) is an approach to generate images from a latent code.
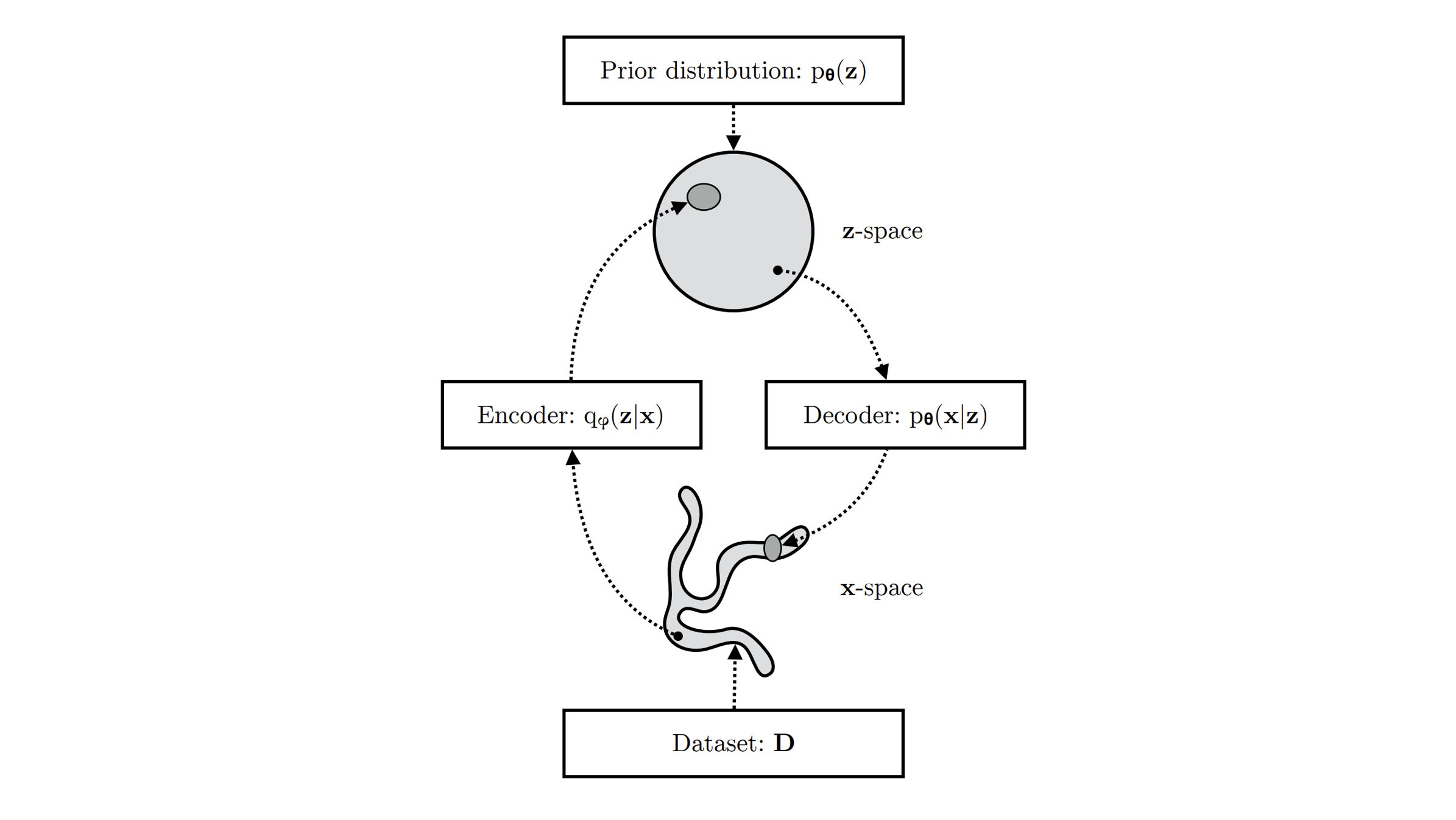
 The name "variational" comes from the factor that we use probability distributions to describe and . Instead of resorting to a deterministic procedure of converting to , we are more interested in ensuring that the distribution can be mapped to a desired distribution , and go backwards to .
The name "variational" comes from the factor that we use probability distributions to describe and . Instead of resorting to a deterministic procedure of converting to , we are more interested in ensuring that the distribution can be mapped to a desired distribution , and go backwards to .
 Since it's hard to directly access (the decoder) and (the encoder), we consider the following two proxy distributions to approximate them:
Since it's hard to directly access (the decoder) and (the encoder), we consider the following two proxy distributions to approximate them:
- : The proxy for with learnable parameter . We will make it Gaussian to simplify the computation
- : The proxy for with learnable parameter . We will also make it Gaussian to simplify the computation So the whole procedure of VAE can be
ELBO in VAE Setting
In variational inference, minimizing the difference (here to minimize the KL divergence) between two probability distributions is equivalent to maximizing the ELBO. Here, we need to minimize , that is, to maximize
However, the ELBO above may not too useful because it involves , something we have no access to. So we need to do something more:
where in the last line we replace by its proxy , and there are two terms:
- Reconstruction. The first term is about the decoder. We want the decoder to produce a good image if we feed a latent into the decoder. So, we want to maximize . (We sample from real distribution , and the goal of decoder is to approximate to ). The expectation here is taken with respect to the samples conditioned on
- Prior Matching. The second term is the KL divergence for the encoder. We want the encoder to turn into a latent vector such that the latent vector will follow our choice of (good) distribution such as a Gaussian distribution. To conclude, the training goal will be
- Decoder. For given , find to maximize
- Encoder. For given , find to minimize
Training VAE
Encoder
We know that is generated from the distribution . We also know that should be simple as a Gaussian. Assume that for any give input this Gaussian has a mean and a covariance matrix . We use a deep neural network (DNN) to predict them:
Therefore, the samples can be sampled from the Gaussian distribution
Decoder
The decoder is implemented through a neural network, denoted as . The job of the decoder network is to take a latent variable and generates an image :
Let's make one more assumption that the decoded image and the ground truth image is Gaussian, that is
Then, it follows that the distribution (marked to be Gaussian)
where is the dimension of . This equation says that the maximization of the likelihood term in ELBO is literally just the loss between the decoded image and ground truth.
Loss Function
To approximate the expectation, we use Monte-Carlo simulation:
where is the -th sample in the training set, and the distribution is
Now we have the training loss of VAE
where the first term can be simplified to the loss between and as mentioned above, and the second term can be simplified by the solution of KL divergence between two Gaussian distributions:
and in this case , thus
where is the dimension of the vector
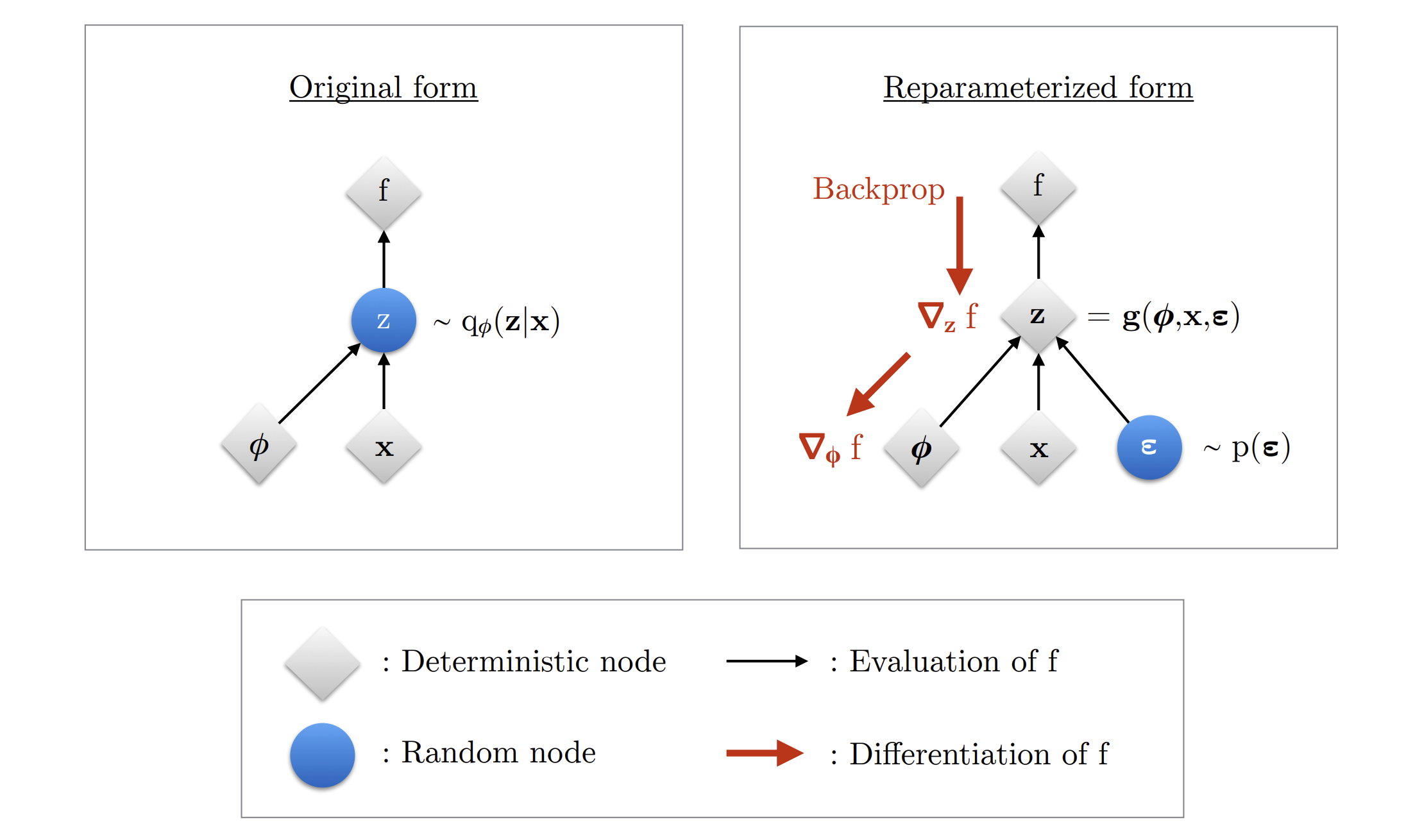
Reparameterization
Note that the latent variable in the loss function is sampled from , which cannot be differentiated during the back-propagation process. So we need to express as some differentiable transformation of another random variable , given and
where the distribution of random variable is independent of and .
Specifically, the distribution can be written as:
where . By this way, the gradient of the loss function can be back-propagated to the parameter
Visualization of Latent Space
The main benefit of a variational autoencoder is that we're capable of learning smooth latent state representations of the input data.
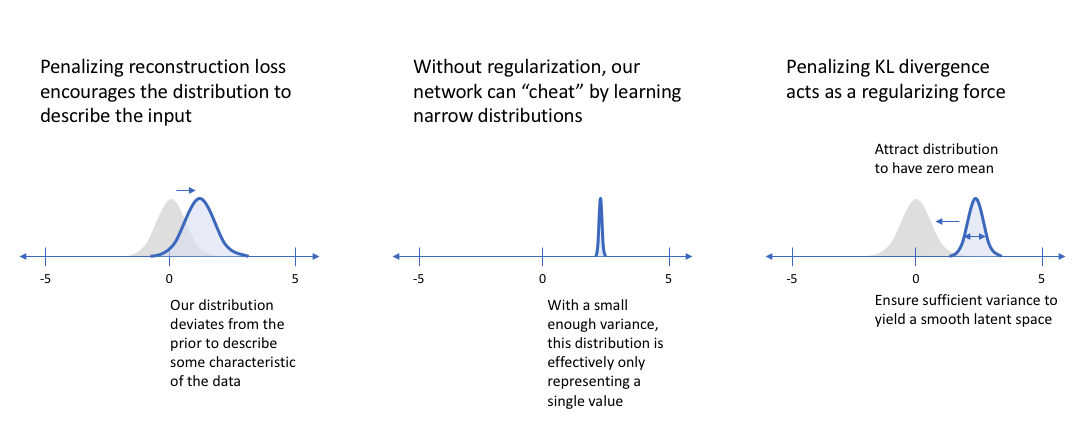
For standard autoencoders, we simply need to learn an encoding which allows us to reproduce the input. As you can see in the left-most figure, focusing only on reconstruction loss does allow us to separate out the classes (in this case, MNIST digits).
However, there's an uneven distribution of data within the latent space. In other words, there are areas in latent space which don't represent any of our observed data. So we cannot just simply sample from the latent space to generate realistic images.
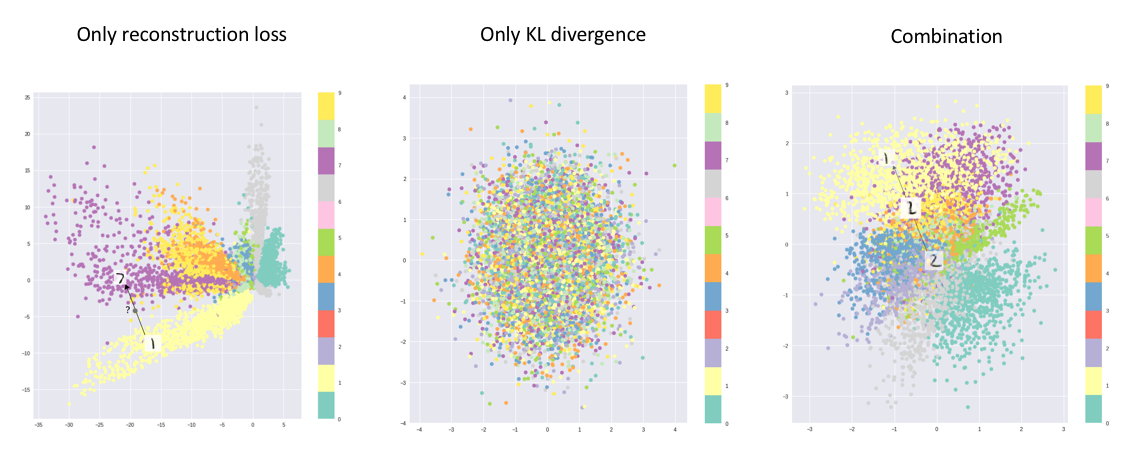 On the flip side, if we only focus only on ensuring that the latent distribution is similar to the prior distribution (through our KL divergence loss term), we end up describing every observation using the same unit Gaussian. So we failed to describe the original data from the latent space.
On the flip side, if we only focus only on ensuring that the latent distribution is similar to the prior distribution (through our KL divergence loss term), we end up describing every observation using the same unit Gaussian. So we failed to describe the original data from the latent space.