Overview
Diffusion models are incremental updates where the assembly of the whole gives us the encoder-decoder structure. The transition from one state to another is realized by a denoiser.
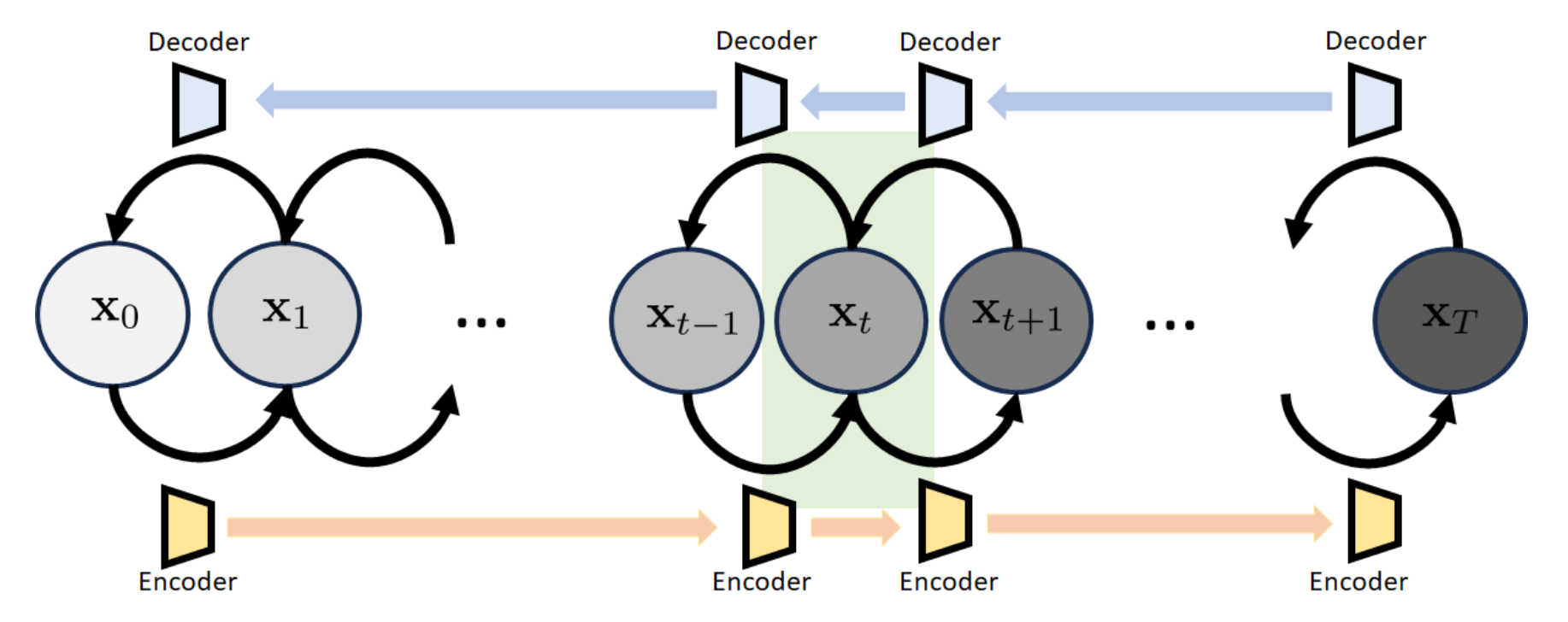 The model whose structure is shown above is called the variational diffusion model (VDM). The model has a sequence of states
The model whose structure is shown above is called the variational diffusion model (VDM). The model has a sequence of states
- : the original image, which is the same as in VAE
- : the latent variable, which is the same as in VAE, and we want to make it Gaussian:
- : the intermediate states, which are also the latent variables, but not white Gaussian
Building Blocks
Transition Block
The -th transition block consists of three states and . There are two possible paths to get to state
![]()
- The forward transition that goes from to . The associated transition distribution is . That is, we can sample from for given . Just like VAE, we do not have access to , so we will approximate it by a Gaussian
- The reverse transition goes from to . Again, we never know so we use another Gaussian to approximate it
Initial Block
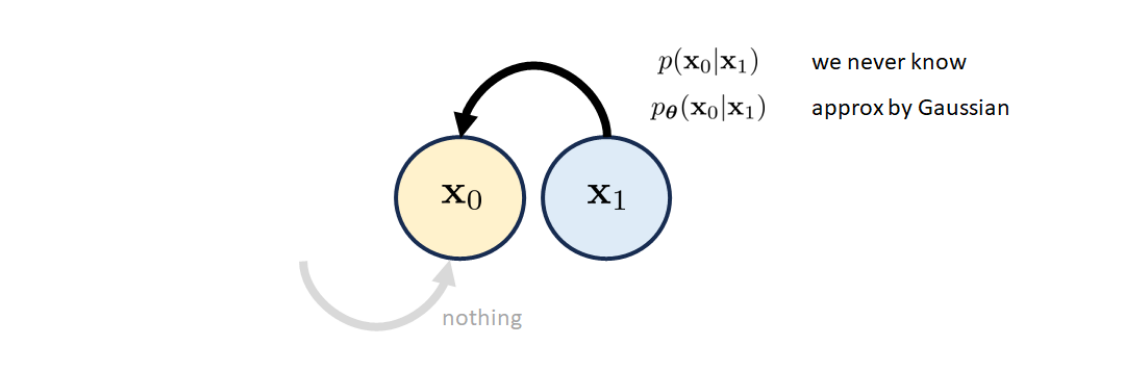 Just without forward path.
Just without forward path.
Final Block
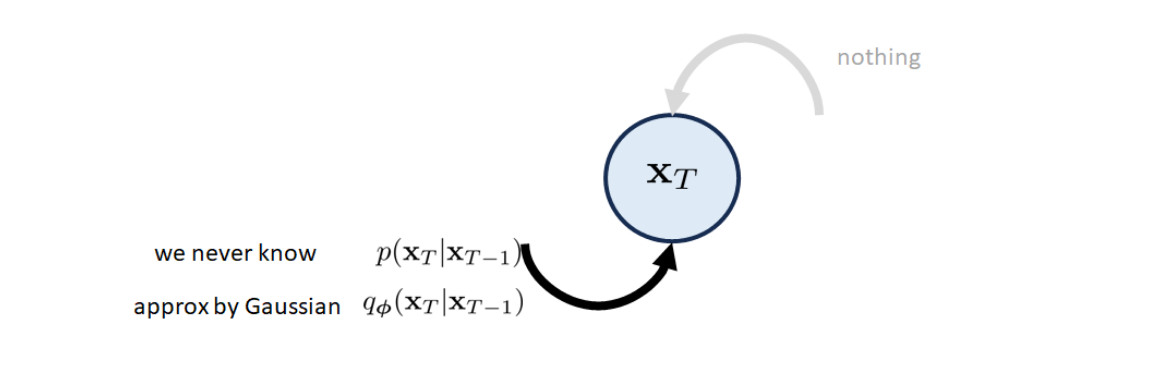 Just without reverse path, and the final variable should be Gaussian
Just without reverse path, and the final variable should be Gaussian
Transition Distribution
In a denoising diffusion probabilistic model, the transition distribution is defined (yes, this is defined, not derived by training) as
That is, the transition distribution is a Gaussian with mean and variance . The choice of the scaling factor is to make sure that the variance magnitude is preserved so that it will not explode and vanish after many iterations
Tip
and are chosen so that the distribution of will become when is large enough.
From this transition distribution, we can obtain how will be distributed if we are given :
where
![]()
Evidence Lower Bound
Like in VAE, we need to maximize the ELBO to train the model, the ELBO in variational diffusion model is
The ELBO here consists of three components:
- Reconstruction. This term is based on the initial block. We use the log-likelihood to measure how good the neural network associated with can recover from the latent variable . The expectation is taken with respect to the samples drawn from during the encoding process.
- Prior Matching. The prior matching term is based on the final block. We use KL divergence to measure the difference between and . We want how is generated, , to be as close to our desired , namely , as possible. The samples here are which are drawn from because this distribution provides the forward sample generation process.
- Consistency. The consistency term is based on the transition blocks, which uses the KL divergence to measure the deviation between the forward path and the reverse path.
Proof of ELBO
Recall by the definition of ELBO, we have
This means that ELBO is an evidence lower bound for , and now we try to estimate it. Let's define the notation: means the collection of all state variable from to . We recall that the prior distribution is the distribution of the image , so
With Jensen's inequality, which states that for any random variable and any concave function , it holds that , so we have
where the first item can be decomposed into two parts:
and the second term is
where the last line used:
Rewrite the Consistency Term
If we want to maximize the ELBO above, we need to handle two opposite directions: and in the consistency and prior matching term. However, we could use Bayes' Theorem to avoid this:
The "" step conditions the probability on since we are primarily concerned with generating the data in denoising diffusion models. By introducing this conditioning on , we aim to incorporate information about the full data trajectory when estimating .
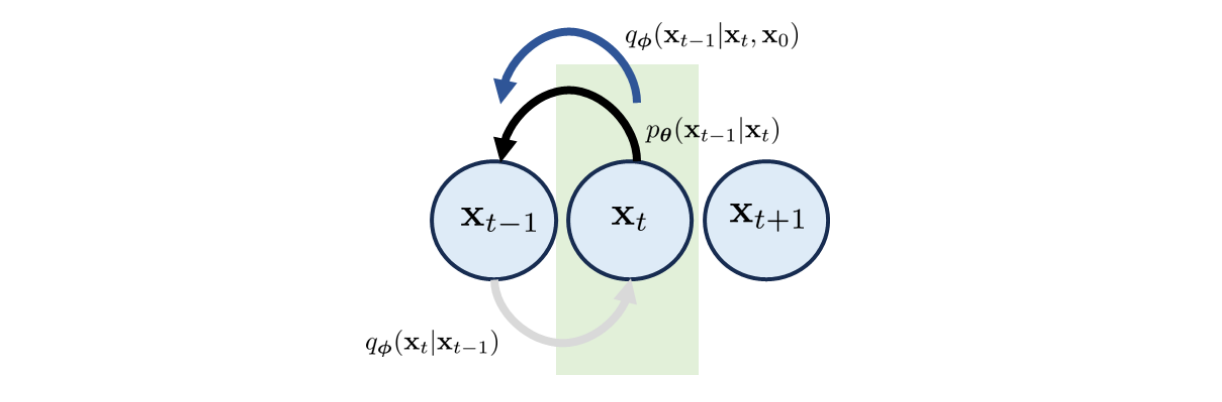 For diffusion models, the reverse process can now be estimated with a noise predictor that approximates the distribution of given . The ELBO maximization will involve minimizing the KL divergence between the learned model and the posterior , that is, the new consistency term.
For diffusion models, the reverse process can now be estimated with a noise predictor that approximates the distribution of given . The ELBO maximization will involve minimizing the KL divergence between the learned model and the posterior , that is, the new consistency term.
To be specific, starting from the Jenson inequality in section Proof of ELBO above:
And now we can apply Bayes' Theorem in the second term
Then we could continue the inequality
Now we have the new ELBO, where
and
To conclude
- Reconstruction. The new reconstruction term is the same as before. We are still maximizing the log-likelihood.
- Prior Matching. The new prior matching is simplified to the KL divergence between and . The change is due to the fact that we now condition upon . Thus, there is no need to draw samples from and take expectation.
- Consistency. The new consistency term is different from the previous one in two ways. Firstly, the running index starts at and ends at . Previously it was from to . Accompanied with this is the distribution matching, which is now between and . So, instead of asking a forward transition to match with a reverse transition, we use to construct a reverse transition and use it to match with
Derivation of the transition distribution given the initial state
Recall the definition of
and the transition distribution
with how we got via Bayes' Theorem
Then we get
Therefore
We know the product of Gaussians must also be a Gaussian, thus we just need to find the mean and variance of the product. For simplicity, treat the vectors as scalars. Consider the following mapping:
Then we need to analyze the function
The minimizer of is the mean of the resulting Gaussian. So, calculate
Setting yields . Note that , so
Similarly, since
And this gives us
Now we know the distribution of
Therefore, we can calculate the ELBO of VDM! Through some boring algebraic calculation (assuming as Gaussian):
So we get
We don't need to train the second term since each step of is fixed so there is no parameters to learn (the s are typically human-designed), and the is also fixed as a Gaussian
Training and Inference
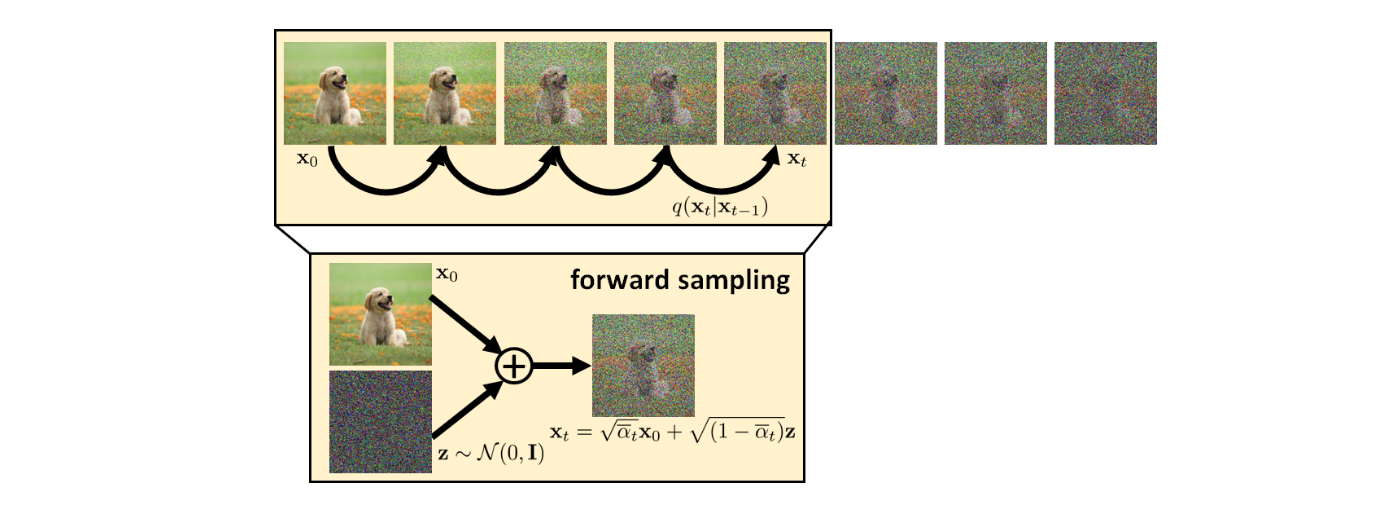 In the ELBO we know
In the ELBO we know
But what about ? Like in VAE's encoder, we could define it as
where is a trainable network with parameter . Now we get
Therefore ELBO can be simplified into
The first term is (using and )
Now we get
And therefore the loss function
Ignoring the constants and expectations, the main subject of interest, for a particular , is
So this is a denoising problem: we need to find a network such that the denoised image will be close to the ground truth .
Training Process
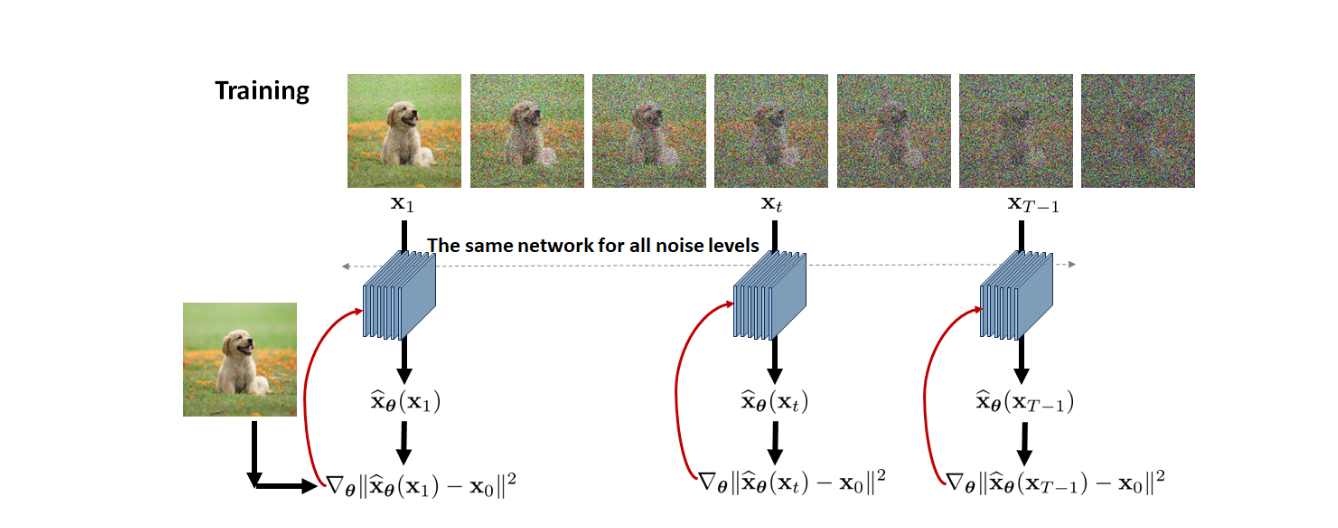 For every image in the training dataset:
For every image in the training dataset:
- Repeat the following steps until convergence
- Pick a random time stamp
- Draw a sample , i.e.,
- Take gradient descent step on
Inference Process
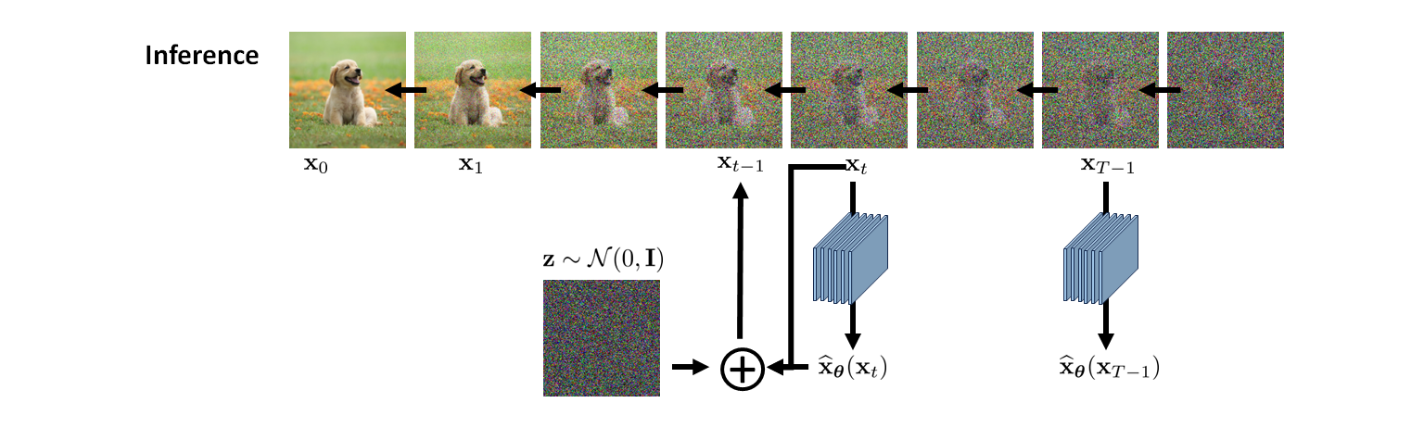 Once the denoiser is trained, we can apply it to do the inference. The inference is about sampling images from the distributions over the sequence of states . Since it is the reverse diffusion process, we need to do it recursively via:
Once the denoiser is trained, we can apply it to do the inference. The inference is about sampling images from the distributions over the sequence of states . Since it is the reverse diffusion process, we need to do it recursively via:
This leads to the inferencing algorithm
- Given a white noise vector
- Repeat the following for
- Calculate using the trained denoiser
- Update according to
Inversion by Direct Denoising (InDI)
If we look at the updating equation above, we could see the following form:
The first term is easy to understand, but what is "denoise"?
More about Denoise
Denoising is a generic procedure that removes noise from a noisy image. Given the observation model
A classical solution to find an estimator such that the mean squared error is minimized is
So, if we assume that during the forward path
we can find the solution of denoiser
Such a denoiser is called the minimum mean squared error (MMSE) denoiser. MMSE denoiser is not the "best" denoiser; It is only the optimal denoiser with respect to the mean squared error. Since mean squared error is never a good metric for image quality, minimizing the MSE will not necessarily give us a better image.
Incremental Denoising Steps
The previous section tells us that an MMSE denoiser is equivalent to the conditional expectation of the posterior distribution. Now we introduce incremental denoising. Suppose that we have a clean image and a noise image . Our goal is to form a linear combination of and via a simple equation
Now, consider a small step , then it holds that
If we define as the left hand side, replace by , and write as , then the above equation will become
where is a small step in time. This equation gives us an inference step. If you tell us the denoiser and suppose that you start with a noisy image , then you can iteratively apply this equation to retrieve the images
Equivalent Interpretations
Predicting noises
As discussed above, a Variational Diffusion Model can be trained by simply learning a neural network to predict the original natural image form an arbitrary noised version and its time index .
This interpretation is from the parameterization of , that is
And we can rewrite this to
Now we can change to a function of rather than , that is
Therefore, now we could set our predicted transition mean as
And after some calculations, we just need to optimize
We have therefore shown that learning a VDM by predicting the original image is equivalent to learning to predict the noise; empirically, however, some works have found that predicting the noise resulted in better performance
Predicting scores
As we have concluded
by Tweedie's Formula, we have
And we know the best estimate for the true mean of given is , now we get (write as for convenience)
Now we get another why to express
Therefore, we can also set our approximate denoising transition mean as
And the corresponding optimization problem becomes
One more problem is how to calculate , this would be easy if we apply the relationship used in predicting noises
This is equal to
Now we get
Tip
The score function measures how to move in data space to maximize the log probability; intuitively, since the source noise is added to a natural image to corrupt it, moving in its opposite direction "denoises" the image and would be the best update to increase the subsequent log probability.
Score-Matching Langevin Dynamics (SMLD)
In this section we dive into the intuition of the score-matching interpretation.
Energy-based Models
To begin to understand why optimizing a score function makes sense, we shall first introduce energy-based models. Remember the form of Boltzmann Distribution, we have
where is an arbitrarily flexible, parameterizable function called the energy function, and is a normalizing constant to ensure that . One way to learn this distribution is MLE, but this requires tractably computing the normalizing constant , which may not be possible for complex functions.
One way to avoid calculating or modeling the normalization constant is by using a neural network to learn the score function of distribution instead. This can be done by taking the derivative of the log of both sides of the equation above
which can be freely represented as a neural network without involving any normalization constants. The score model can be optimized by minimizing the Fisher Divergence with the ground truth score function
Langevin Dynamics
Imagine that we are given a distribution and suppose that we want to draw samples from . Langevin dynamics is an iterative procedure that allows us to draw samples according to the following equation
where is the step size which users can control, and is white noise.
Note that if we ignore the noise term at the end, the Langevin dynamics equation is literally gradient descent. The descent is carefully chosen that will converge to the distribution .
The goal of this descent sampling process is to find a where the probability is the highest, which is equivalent to solving the optimization
Warning
Note that this is not MLE. In maximum likelihood, the data point is fixed but the model parameters are changing. Here, the model parameters are fixed but the data point is changing.
And now we can understand the noise term , which literally changes the gradient descent to stochastic gradient descent. Instead of shooting for the deterministic optimum, the stochastic gradient descent climbs up the hill randomly, so that there would be a lower probability to stuck into a local maximum
However, we actually do not care about the maximum of , which is the final goal of the descent process. Instead, we care about the sampling process itself. As well as our descent algorithm is good at find peaks, then by repeatedly initialize the algorithm at a uniformly distributed location, we will eventually collects samples that will follow the distribution we want to match.
Info
Suppose we initialize uniformly distributed samples . We run Langevin updates for steps. The histograms of generated samples are shown in the figures below
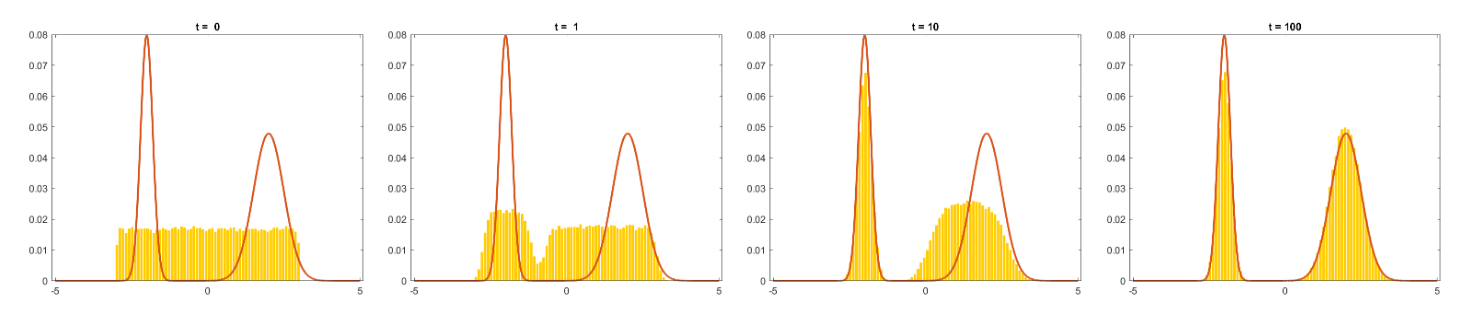
In summary, Langevin dynamics gives us a more intuitive vision into the score-matching problem in energy-based models. In energy-based models, we learn the distribution of by matching a score function with . On the other hand, if we find a good estimation of the descent term in Langevin dynamics, the sampling process would do better in finding a peak in the neighborhood of its initial state , so that by initialize the uniformly in the interval we interested with, the sampling would follow the we want to approximate.