Idea
- BERT stands for *Bidirectional Encoder representation from Image Transformers
- BEIT stands for Bidirectional Encoder representation from Image Transformers
In computer vision, Vision Transformer (ViT) requires more training data than CNNs. However, high quality labeled data is rare and hard to acquire, so we need to develop self-supervised models
BEIT and MAE are designed to self-supervised learning by predicting the masked information. The major difference between these two models is that BEIT predicts the token while MAE predicts the original pixel
Method
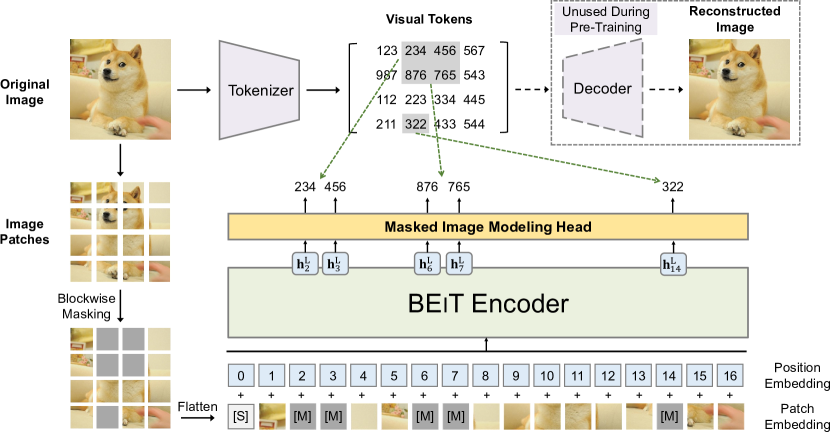
Before pre-training
Train an image tokenizer via autoencoding-style reconstruction, save the learned image-to-token vocabulary
During pre-training
- Randomly mask some proportion of image patches, and replace them with special mask embedding
[M] - Feed the patches (including the masked embeddings) into a backbone vision Transformer
- The aim is to predict the visual tokens of the original image that the decoder could use to reconstruct the image (though the decoder is not used in this pre-training period)
Fine-tune on downstream tasks
such as classification, semantic segmentation
Contribution
BEIT has demonstrated for the first time that generative pre-training can achieve better fine-tuning results than contrastive learning, excelling in image classification and semantic segmentation tasks. More importantly, by eliminating the reliance on supervised pre-training, BEIT can efficiently utilize unlabeled images to scale Vision Transformers to large model sizes. It is believed that the "generative self-supervised renaissance" initiated by BEIT in the visual domain will accelerate the field towards "the BERT moment of CV"