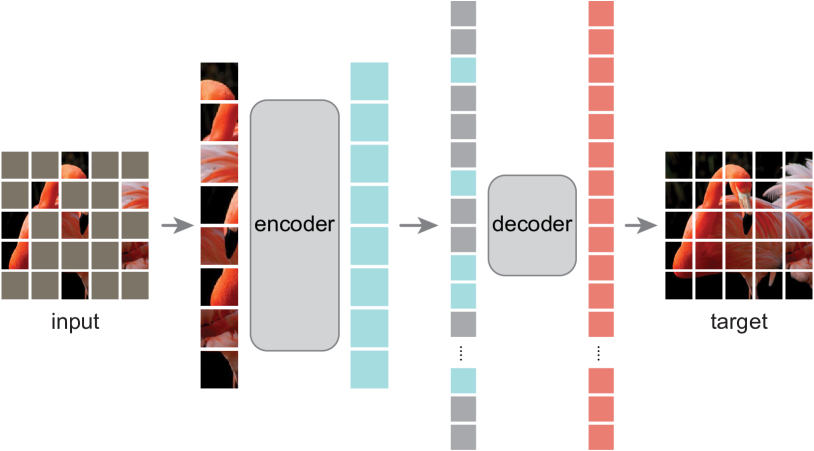
Idea
Develop an asymmetric encoder-decoder model, where
- A large random subset of image patches is masked out, and the visible patches are taken as the input of the encoder
- Masked tokens are introduces after the encoder, and the full set of encoded patches and mask tokens is processed by a small decoder that aims to reconstruct the original image in pixels.
- The two steps above is during the pre-training process. After per-training, the decoder is discarded and the encoder is applied to uncorrupted images for recognition tasks
Questions
- Why mask a large ratio of image patches (such as 75%):
- It optimizes accuracy since the task is becoming challenging
- Reduce memory and time costs during pre-training