Idea
Previous Works
- ELMo: use bidirectional information(the model can access the contexts above and below) on traditional architectures (RNNs)
- GPT: use unidirectional information (left to right in particular), on more modern architectures (transformers)
Innovation
Train transformers on bidirectional information
Framework
Steps
- Pre-training: the model is trained on unlabeled data over different pre-training tasks
- Fine-tuning: first initialize the model with the pre-trained parameters, and all of the parameters are fine-tuned using labeled data from the downstream tasks
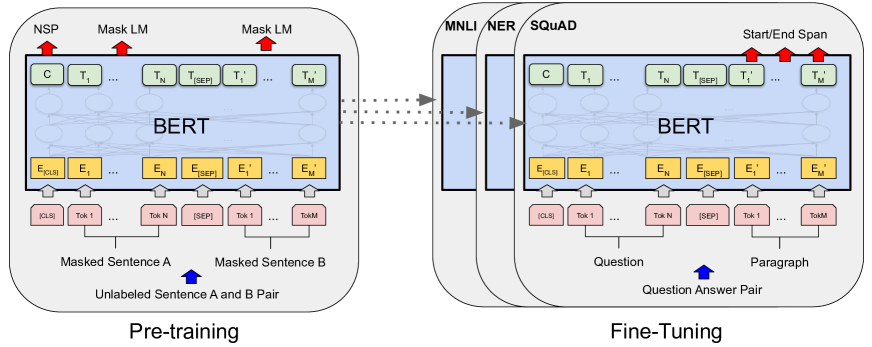
Tip
[CLS]is a special token stands for classification task; Since the sequence input of BERT can be a sentence pair like (Question, Answer), so another special token[SEP]is used to separate two sentences.
Embedding
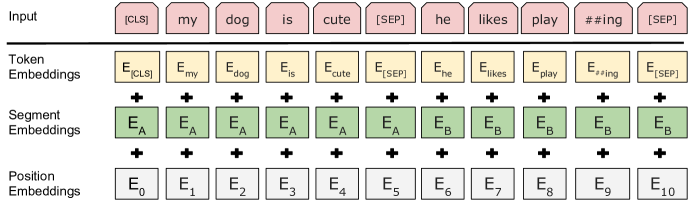
- Token Embeddings: See Word2Vec
- Position Embeddings: See positional encoding in transformers
- Segment Embedding: To locate the sentence