Idea
If we modify traditional CNNs according to modern Transformer architecture, they may perform better. The conclusion is that, in terms of Computer Vision, we cannot say Transforms is just better than CNNs.
Improvement
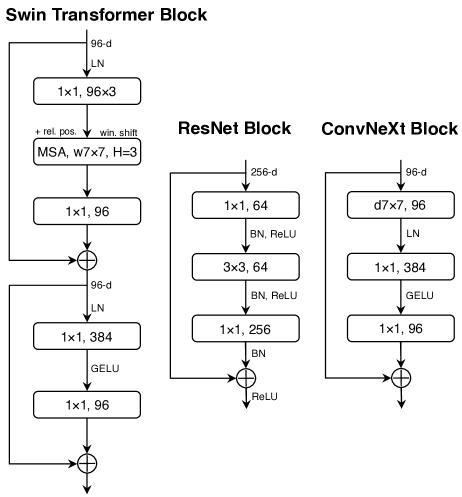
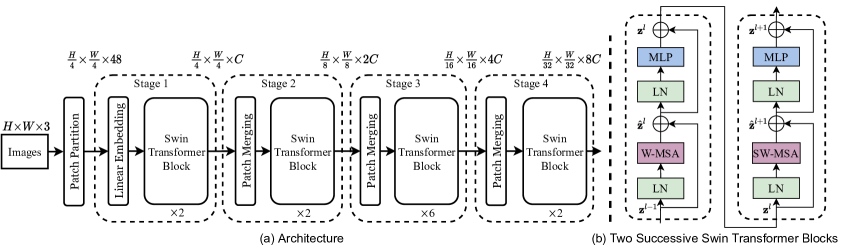
Architecture
Stage Ratio
Adjust block size referring to Swin Transformer, which is . Therefore, improve the block size of each stage in ResNet-50 to
{kind=link}
Patchify Stem
Use a stem layer to do the similar work as the patching layer in vison Transformers does.
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)Group Convolution
Divides the input channels into distinct groups, each of which is convolved with its own set of filters. This approach allows for a reduction in the number of parameters and computational complexity.
Inverted Bottleneck
Unlike the traditional bottleneck layer, the inverted bottleneck has a hidden dimension of the MLP block is four times wider than the input dimension (Like the feed forward layer in Transformer architecture, which may retain more information.
Larger Kernel Size
In vision transformers, the self-attention enables each layer to have a global receptive field. Large kernel size could achieve this, too. In experiment, kernel size performs the best
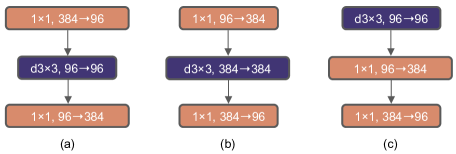 The figure above: (a) is a ResNeXt block; in (b) we create an inverted bottleneck block and in (c) the position of the spatial depth-wise conv layer is moved up (since in Transformers the MSA block is placed prior to the MLP layers)
The figure above: (a) is a ResNeXt block; in (b) we create an inverted bottleneck block and in (c) the position of the spatial depth-wise conv layer is moved up (since in Transformers the MSA block is placed prior to the MLP layers)
Some detail optimization
- Switch to GeLU from ReLU
- Use less activation functions (as in Transformers)
- Less normalization layer and use Layer Normalization instead of Batch Normalization