Idea
Introduce a pixelwise prediction layer at the end of CNN sequences (replacing the original fully connected layer used for classification like in VGG), so that the output segmentation have the same size of the input image
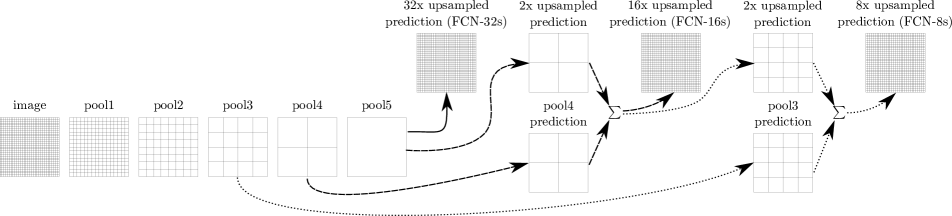
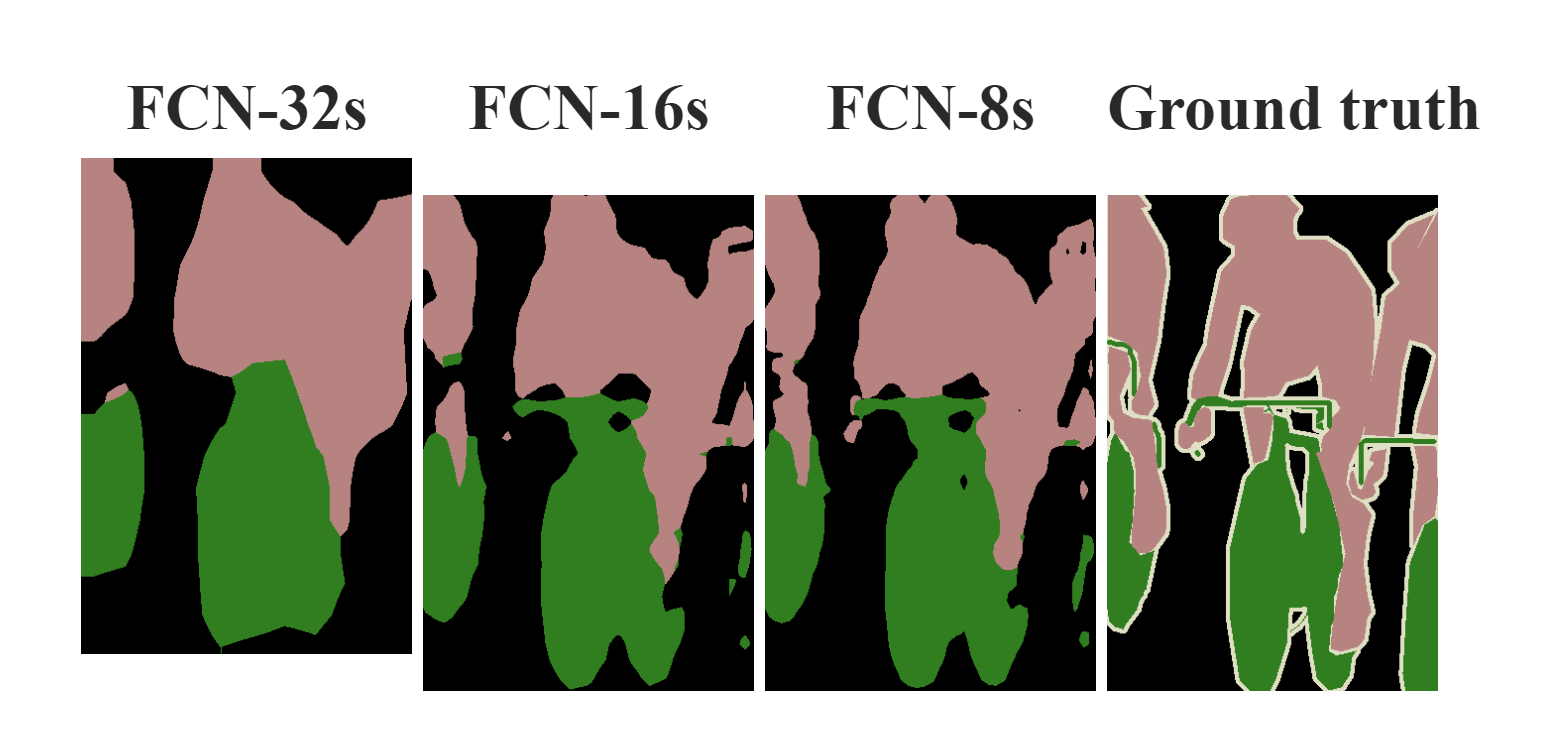
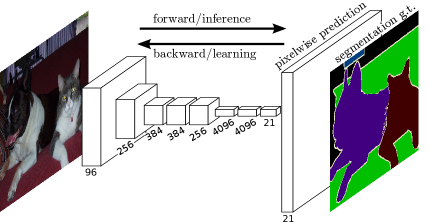 As the figure shown below, we have different ways to do the unsampling in this last layer. FCN-32s applies 32x unsampled prediction directly from pool5. FCN-16s first applies a 2x unsampled prediction from pool5 and then combine the result with the information from pool3, which improves segmentation accuracy. FCN-8s further optimized the accuracy by combing the information in pool3.
As the figure shown below, we have different ways to do the unsampling in this last layer. FCN-32s applies 32x unsampled prediction directly from pool5. FCN-16s first applies a 2x unsampled prediction from pool5 and then combine the result with the information from pool3, which improves segmentation accuracy. FCN-8s further optimized the accuracy by combing the information in pool3.
Related Work
FCN can be seen as a asymmetric Encoder-Decoder network, where the CNNs constitute the encoder and the pixelwise prediction layer as well as the unsampling layers before it are the decoder. As for symmetric Encoder-Decoder network for segmentation tasks, see U-Net