Idea
Append two types of attention modules on top of dilated FCN, which model the sematic interdependencies in spatial and channel dimensions respectively.
Architecture
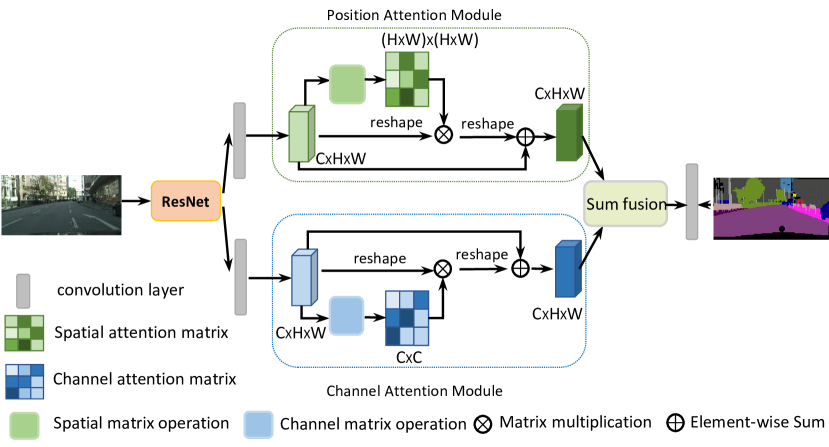
Dual Attention Module
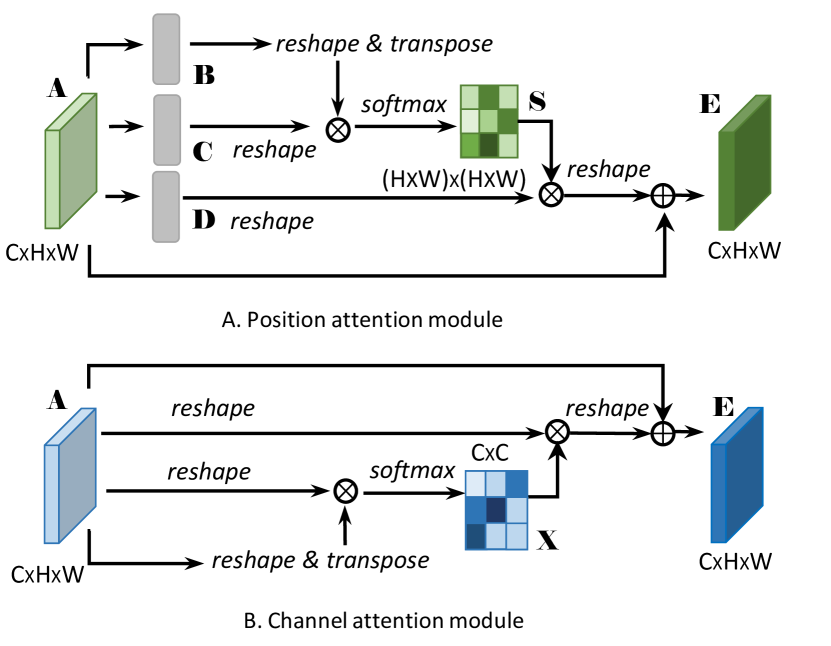
Positional Attention Module
Just like the attention mechanism in Transformer, here we may consider as key, as query and as value. The difference is that here we apply convolution layers instead of a linear layer to convert to , and . The final self-attention score is
Channel Attention Module
Apply channel-wise self-attention