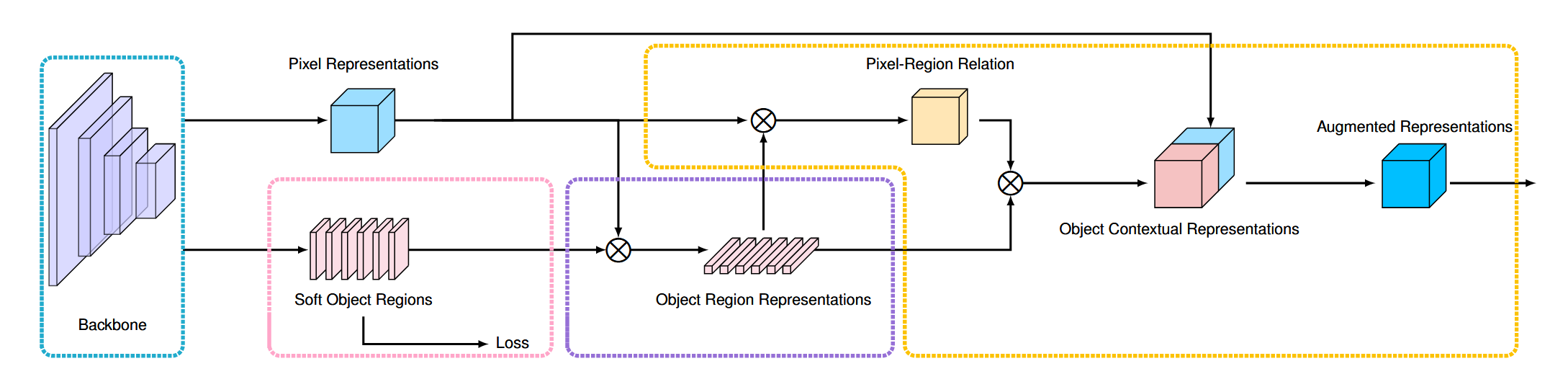
Idea
- For each pixel, aggregating the pixel with its region information (the category this pixel belongs to predicted by the backbone network, regularized by the ground-truth segmentation with a auxiliary loss during training) to obtain Object Region Representations
- Compute the relation between each pixel and each object region, and augment the representation of each pixel with the object-contextual representation which is a weighted aggregation of all the object region representations.
Segmentation Transformer
The pipeline above can be rephrased into the following transformer encoder-decoder architecture
![]()