Motivation
- The previous training procedure of R-CNNs includes many heuristics and hyperparameters that are costly to tune.
- Detection datasets contain an overwhelming number of easy examples and a small number of hard examples.
- Automatic selection of these hard examples can make training more effective and efficient
Imbalance of foreground objects and background objects
This training set for object detection is distinguished by a large imbalance between the number of annotated objects and the number of background examples (image regions not belonging to any object class of interest), where the background examples could be x more than foreground examples.
A standard solution to solve this issue is called bootstrapping (and now often called hard negative mining). Bootstrapping was introduced for training face detection models. The key idea of this method is to gradually grow, or bootstrap, the set of background examples by selecting those examples for which the detector triggers as false alarm. This strategy leads to an iterative training algorithm that alternates between updating the detection model given the current set of examples, and then using the updated model to find new false positives to add to the bootstrapped training set.
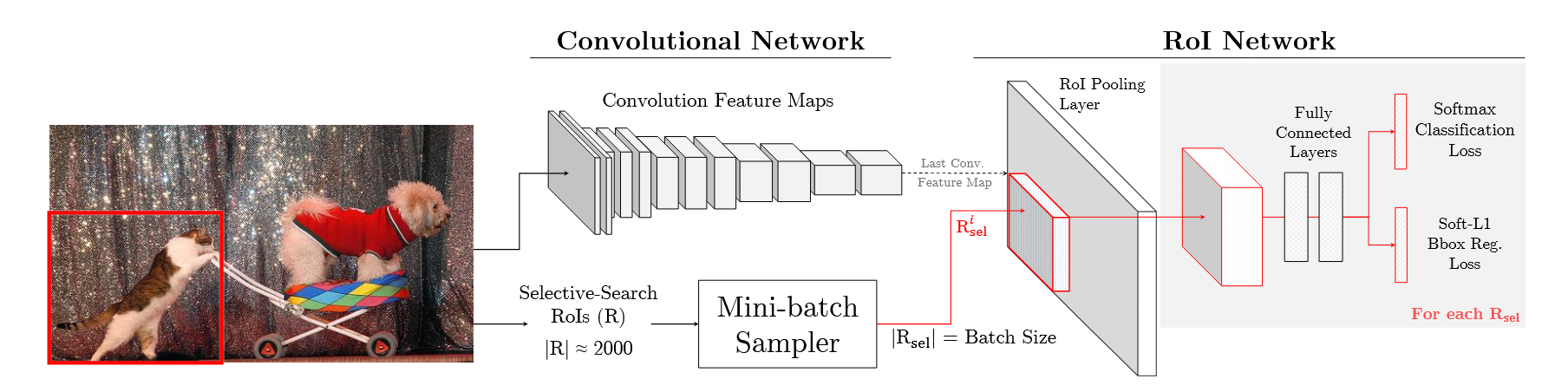
The traditional training process (e.g. Fast R-CNN)
 FRCN is trained using stochastic gradient descent (SGD). The loss per example RoI is the sum of a classification log loss and a localization loss
FRCN is trained using stochastic gradient descent (SGD). The loss per example RoI is the sum of a classification log loss and a localization loss
To share convolutional network computation between RoIs, SGD mini-batches are created hierarchically. For each mini-batch, images are first sampled from the dataset, and then RoIs are sampled from each image. (In practice and ).
Foreground RoIs
For an example RoI to be labeled as foreground fg, its intersection over union (IoU) overlap with a ground-truth bounding box should be at least
Background RoIs
A region is labeled background bg if its maximum IoU with ground truth is in the interval [bg_lo, 0.5). A lower threshold of bg_lo = 0.1 is used by FRCN, and is hypothesized to crudely approximate hard negative mining. The assumption is that regions with some overlap with the ground truth are more likely to be the confusing or hard ones.
Balancing fg-bg RoIs
FRCN designed heuristics to selective sample data from the training data in order to balance the foreground-to-background ratio in each mini-batch to a target of by under-sampling the background patches at random.
OHEM Approach
Although each SGD iteration samples only a small number of images (like above), each image contains many example RoIs (like above) from which we can select the hard examples rather than a heuristically sampled subset.
For an input image at SGD iteration
- Compute a conv feature map using the conv network
- RoI network uses this feature map and the all the input RoIs (instead of a sampled min-batch) to do a forward pass
- Hard examples are selected by sorting the input RoIs by loss and taking the example for which the current network performs worst
- Remove all lower loss RoIs that have high overlap with the selected region via Non-maximum Suppression
- The selected hard regions are fed into another copy of the RoI network to compute loss and gradient.
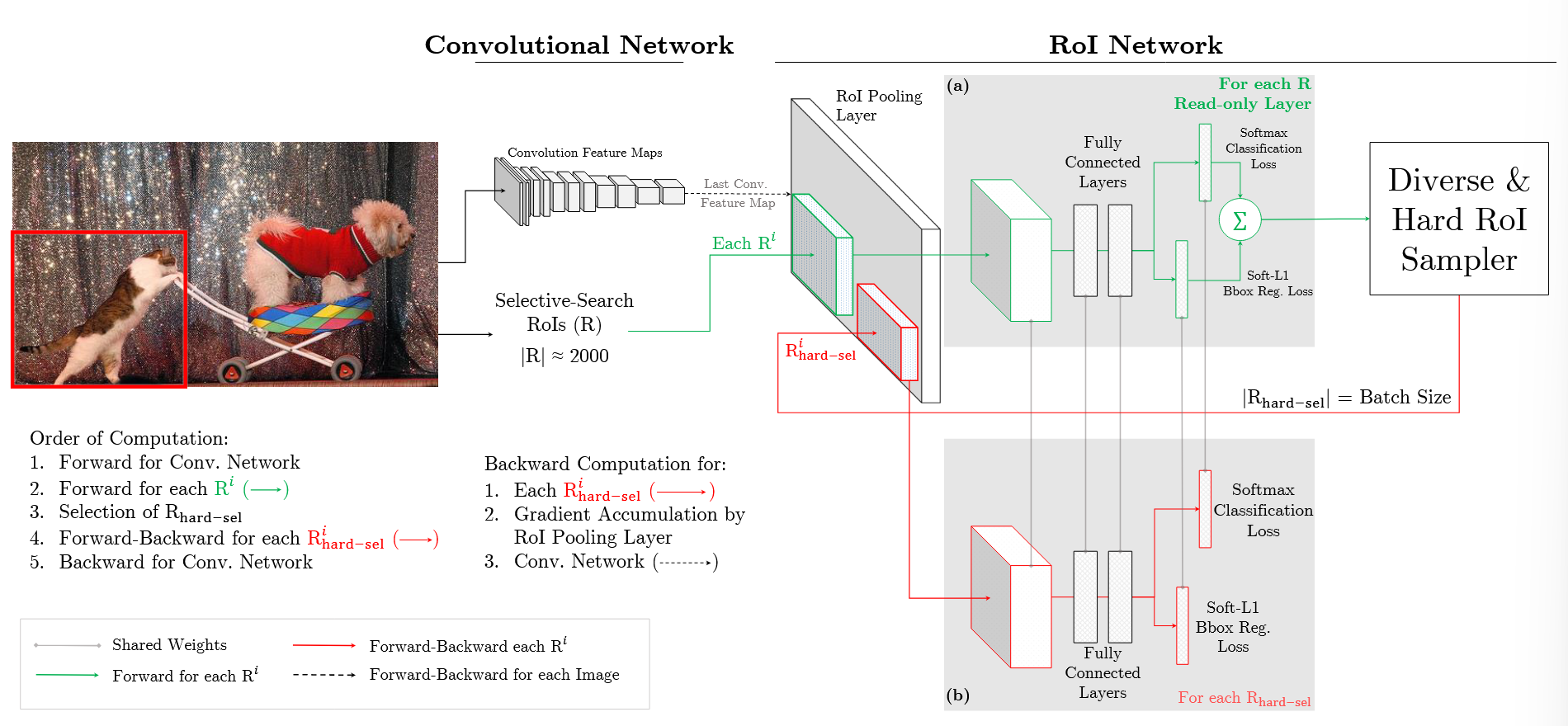
This approach has two benefits
- Dynamically select hard examples to update the model, which is more efficient and effective
- Solve the imbalance of of
fg-bgratio since if any class (eitherfgorbg) were neglected, it loss would increase until it has a high probability of being sampled.