Idea
The limitation of tradition residual network and CNNs : stride convolution operations keep downsampling the original image and losing spatial information so that it is hard to do precise segmentation.
DeepLab v1 comes up with the dilated convolution method to tackle this problem. Though successfully maintain the image size by setting stride from to and applying different dilating rates, the model costs a large amount of memory.
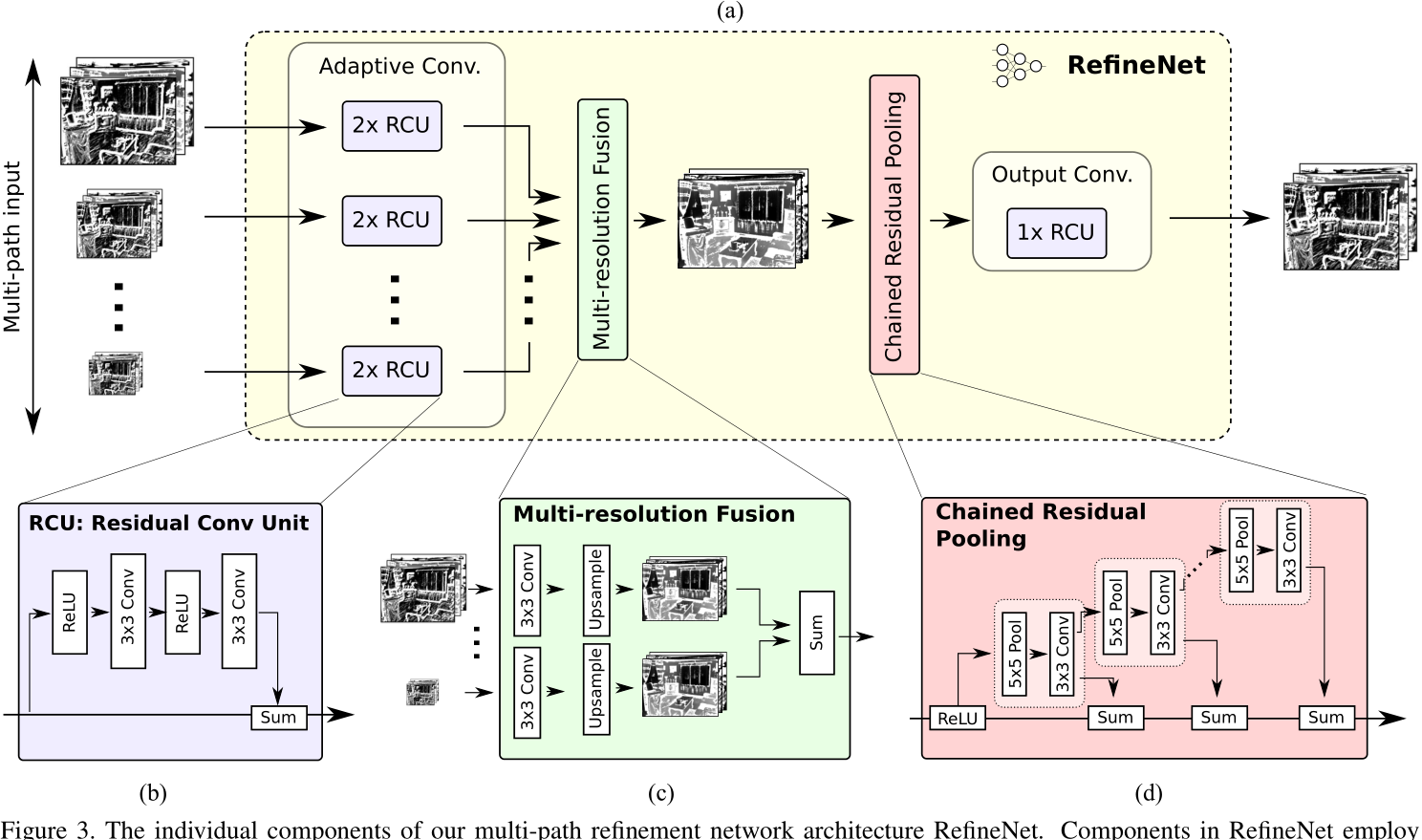
RefineNet proposes a new method to enjoy both the memory an computational benefits while still able to produce effective high-resolution segmentation prediction via multi-path refinement

Architecture
Multi-path Refinement
Each RefineNet block takes in the corresponding downsampling result and the output of the low spatial size RefineNet block.
Residual Convolution Unit
The simplified version of the original convolution unit in the original ResNet, where the batch normalization is removed.
Muti-resolution Fusion
This block fuses all path inputs into a high-resolution feature map. The steps are:
- Use a convolution layer to convert the inputs into the same feature dimension (the smallest one)
- Upsample all the feature maps to the largest resolution of the inputs
- Fuse all the feature maps by summation
Chained Residual Pooling
The pooling aims to capture background context from a large image region. It is able to efficiently pool features with multiple window sizes and fuse them together using learnable weights.