Motivation
- The previous object detection models are designed in an indirect way to tackle the problem, by defining surrogate regression and classification problems on a large set of proposals, anchor or windows centers. This includes many hand-designed procedures such as anchor generation and Non-maximum Suppression
- To simplify these pipelines, the author proposes a end-to-end approach to bypass the surrogate tasks.
General Idea
View the object detection as a direct set prediction problem, that is, directly predicts the final set of boxes without redundant bounding boxes
Set Prediction Loss
Bipartite matching
Let the ground truth set of objects be denoted by , and for the set of predictions. Assuming is larger than the number of objects in the image, we consider also as a set of size padded with (no object). To find a bipartite matching (see in bipartite graphs) between these two sets we search for a permutation of elements with the lowest cost:
where is a pair-wise matching cost
Each element of the ground truth set can be seen as a where is the target class label and is a vector that defines ground truth box center coordinates and its height and width relative to the image size. If is the predicted probability of class of the prediction with index , we define
where
and the IoU loss
Hungarian Loss
In the previous section we find the permutation that best match the set of prediction and the set of ground truth, and then we need to compute the loss function:
Method
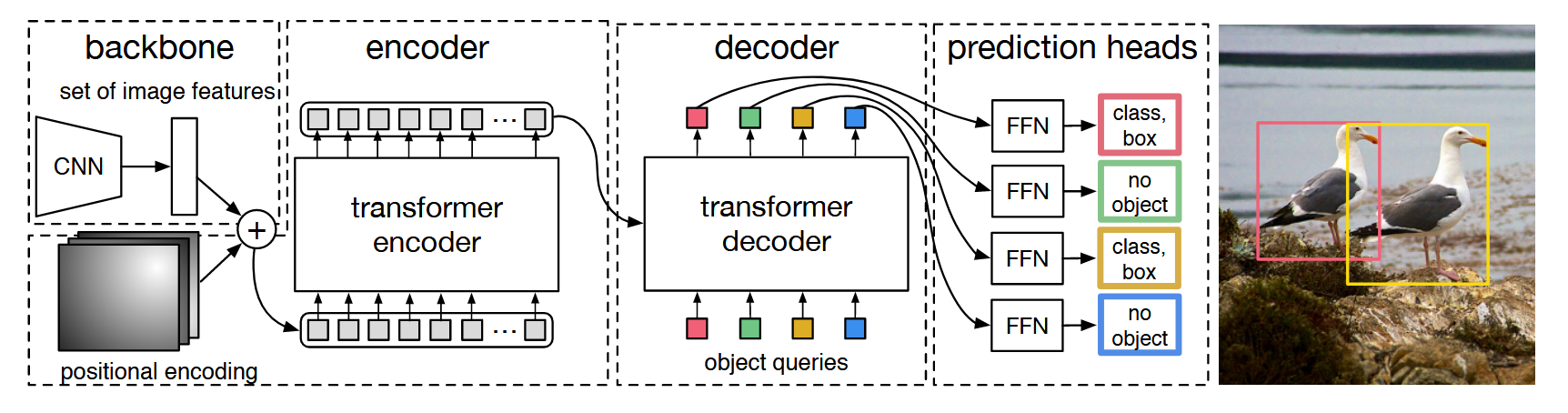
Backbone
Starting from the initial image , a conventional CNN backbone generates a lower-resolution activation map . The typical values are
Transformer Encoder
- a convolution reduces the channel dimension of the high-label activation map from to a smaller dimension , creating a new feature map
- Collapse the spatial dimensions of to and add positional encodings, and then fed into the transformer
Transformer Decoder
The input of the decoder is a sequence of learnable positional encodings called object queries. This can be seen as something like learned anchor boxes, which give the model some prior knowledge about how to bound the boxes etc. but without human design
Prediction Feed-forward networks
Takes in the output of the transformer decoder and obtain the mentioned above