Motivation
- Propose a new model that is faster than SAM in image segmentation
- Apply streaming memory to tackle with video segmentation
Task: prompt-able visual segmentation
The PVS task allows providing prompts to the model on any frame of a video. Prompts can be positive / negative clicks, bounding boxes, or masks, either to define an object to segment or to refine a model-predicted one.
Model
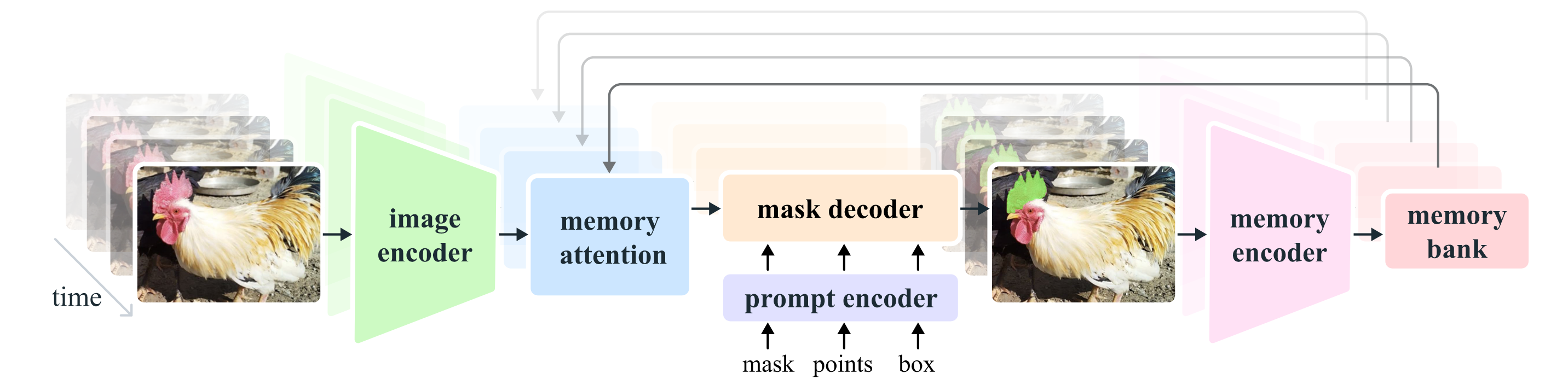
General Process
For a given frame, the segmentation prediction is conditioned on the current prompt and/or on previously observed memories. Videos are processed in a streaming fashion with frames being consumed one at a time by the image encoder, and cross-attend to memories of the target object from previous frames. The mask decoder, which optionally also takes input prompts, predicts the segmentation mask for that frame. Finally, a memory encoder transforms the prediction and image encoder embeddings for use in future frames.
Image Encoder
Use an MAE pre-trained Hiera, which is hierarchical and allows to use muti-scale features during training.
Memory Attention
The role of memory attention is to condition the current frame features on the past frames features and predictions as well as on any new prompts.
We stack transformer blocks, the first one taking the image encoding from the current frame as input. Each block performs self-attention, followed by cross-attention to memories of (prompted / unprompted) frames and object pointers, stored in a memory bank, followed by an MLP.
graph TD A[Current Frame Features] --> B[Image Encoding] B --> C[Transformer Block 1] C --> D[Transformer Block 2] D --> E[...] E --> F[Transformer Block L] subgraph "Memory Bank" H[Past Predictions] J[Object Pointers] end subgraph "Each Transformer Block" K[Self-Attention] L[Cross-Attention] M[MLP] end H --> L J --> L K --> L L --> M N[Efficient Attention Kernels] N -.-> K N -.-> L
Prompt Encoder
The prompt encoder is identical to SAM's
Mask Decoder
Key Designs
- For ambiguous prompts (i.e., a single click) where there my be multiple compatible target masks, we predict multiple masks. This design is important to ensure that the model outputs valid masks on each frame
- Unlike SAM where there is always a valid object to segment given a positive prompt, in the PVS task it is possible for no valid object to exist on some frames (e.g. due to occlusion). To account for this new output mode, an occlusion score is predicted
Two-layer Decoder
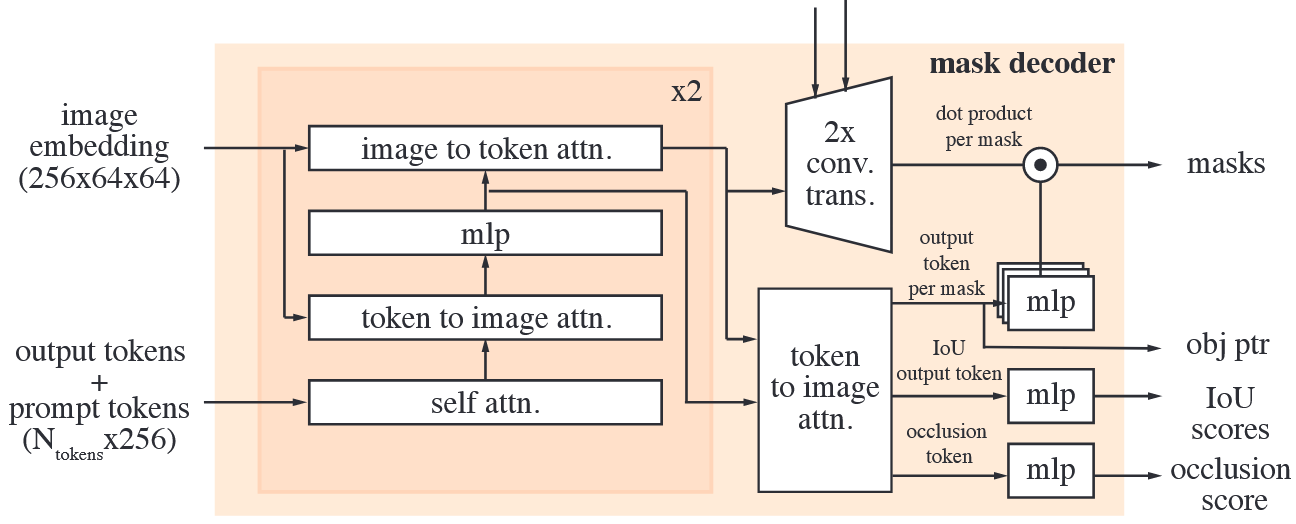 A two-layer decoder updates both the image embedding and prompt tokens via cross-attention. Each decoder layer performs steps:
A two-layer decoder updates both the image embedding and prompt tokens via cross-attention. Each decoder layer performs steps:
- Self-attention on the tokens
- Cross-attention from tokens (as queries) to the image embedding
- A point-wise MLP updates each token
- Cross-attention form the image embedding (as queries) to tokens.
To ensure the decoder has access to critical geometric information the positional encodings are added to the image embedding whenever they participate in an attention layer. Additionally, the entire original prompt tokens are re-added to the update tokens whenever they participate in an attention layer. This allow for a strong dependence on both the prompt token's geometric location and type.
Predict Mask
After running the decoder
- Upsample the updated image embedding by with transposed convolutional layers.
- The tokens attend once more to the image embedding
- Pass the updated token embeddings to s small -layer MLP that outputs a vector matching the channel dimension of the upscaled image embedding
- Predict a mask with a spatially point-wise product between the upscaled image embedding and the MLP's output
Scores and Losses
Two MLP heads are added to produce
- An IoU score
- An occlusion score indicating the likelihood of the object of interest being visible in the current frame
Memory Encoder
The memory encoder generates a memory by downsampling the output mask using a convolutional module and summing it element-wise with the unconditioned frame embedding from the image-encoder, followed by light-weight convolutional layers to fuse the information
graph TD subgraph "Memory Encoder" A[Output Mask] -->|Downsample| C[Element-wise Sum] D[Unconditioned Frame Embedding] --> C C --> E[Lightweight Convolutional Layers] E --> F[Generated Memory] end subgraph "Memory Bank" G[FIFO Queue - Recent Frames] H[FIFO Queue - Prompted Frames] I[Object Pointers] F -->|Store| G F -->|Store| H G --> L[Memory Attention] H --> L I --> L end K[Mask Decoder Output Tokens] -->|Generate| I
Memory Bank
The memory bank retains information about past predictions for the target object in the video by maintaining a FIFO queue of memories of up to recent frames and stores information from prompts in a FIFO queue of up to prompted frames. Both sets of memories are stored as spatial feature maps.
In addition to the spatial memory, we store a list of object pointers as lightweight vectors for high-level semantic information of the object to segment, based on mask decoder output tokens of each frame.