Idea
Apply Vision Transformer (ViT) for semantic segmentation, unlike DPT - Vision Transformers for Dense Prediction, this paper also uses mask Transformer as the decoder.
The class masks make the decoder focuses on specific foreground areas, and could help in extracting more relevant and localized features for segmentation
Architecture
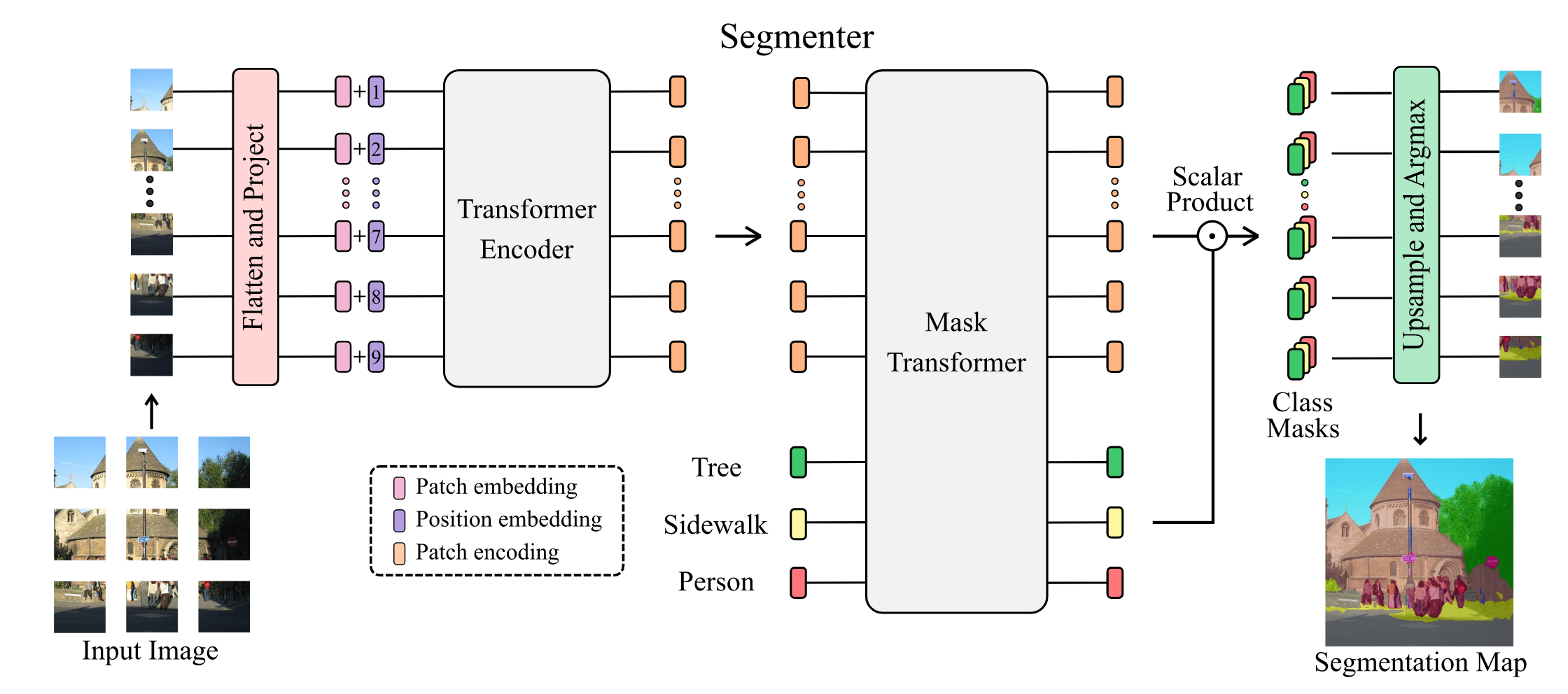
Encoder
Adopt flattening and linear projection as the embedding method. then added with position embedding. Just like the original vision transformer paper
Decoder
The sequence of path encodings is decoded to a segmentation map where is the number of classes.
The decoder learns to map patch-level encodings coming from the encoder to patch-level class scores. Next these patch-level class scores are upsampled by bilinear interpolation to pixel-level scores.
Linear
A point-wise linear layer is applied to the patch encodings to produce patch-level class logits . The sequence is then reshaped into a 2D feature map . A Softmax is then applied on the class dimension to obtain the final segmentation map
Mask Transformer
Introduce a set of learnable class embeddings . Each class embedding is initialized randomly and assigned to a single semantic class.
The class embedding are processed jointly with patch encoding by the decoder.
Mask transformer generates masks by computing the scalar product between L2-normalized patch embeddings and class embeddings output by the decoder
These these mask sequences are reshaped into a 2D mask to form and bilinearly upsampled to the original image size to obtain a feature map .